Content creators and organizations today face a persistent challenge: producing high-quality audio content at scale. Traditional podcast production requires significant time investment (research, scheduling, recording, editing) and substantial resources including studio space, equipment, and voice talent. These constraints limit how quickly organizations can respond to new topics or scale their content production. Amazon Nova 2 Sonic is a state-of-the-art speech understanding and generation model that delivers natural, human-like conversational AI with low latency and industry-leading price-performance. It provides streaming speech understanding, instruction following, tool invocation, and cross-modal interaction that seamlessly switches between voice and text. Supporting seven languages with up to 1M token context windows, developers can use Amazon Nova 2 Sonic to build voice-first applications for customer support, interactive learning, and voice-enabled assistants.
This post walks through building an automated podcast generator that creates engaging conversations between two AI hosts on any topic, demonstrating the streaming capabilities of Nova Sonic, stage-aware content filtering, and real-time audio generation.
What is Amazon Nova 2 Sonic?
Amazon Nova 2 Sonic processes speech input and delivers speech output and text transcriptions, creating human-like conversations with rich contextual understanding. Amazon Nova 2 Sonic provides a streaming API for real-time, low-latency multi-turn conversations, so developers can build voice-first applications where speech drives app navigation, workflow automation, and task completion.
The model is accessible through Amazon Bedrock and can be integrated with key Amazon Bedrock features, including Guardrails, Agents, multimodal RAG, and Knowledge Bases for seamless interoperability across the platform.
Key capabilities:
- Streaming Speech Understanding – Process and respond to speech in real-time with low latency
- Instruction Following – Execute complex multi-step voice commands
- Tool Invocation: Call external functions and APIs during conversations
- Cross-Modal Interaction – Seamlessly switch between voice and text I/O
- Multilingual Support – Native support for English, French, Italian, German, Spanish, Portuguese, and Hindi
- Large Context Window – Up to 1M tokens for maintaining extended conversation context
Understanding the challenge
Podcasts have experienced explosive growth, evolving from a niche medium to mainstream content format. This surge comes from podcasts’ unique ability to deliver information during multitasking activities (commuting, exercising, household tasks) providing an accessibility advantage that visual content can’t match.
However, traditional podcast production faces structural challenges:
Content Scalability: Human hosts require extensive time for research, scheduling, recording, and post-production, limiting output frequency and volume.
Consistency: Human hosts face scheduling conflicts, illness, varying energy levels, and availability constraints that create irregular publishing schedules.
Personalization: Traditional podcasts follow a one-size-fits-all model, unable to tailor content to individual listeners for interests or knowledge levels in real-time.
Resource Efficiency: Quality production requires significant ongoing investment in talent, equipment, editing software, and operational overhead.
Expert Access: Securing knowledgeable hosts across diverse topics remains challenging and expensive, restricting content breadth and depth.
By using the conversational AI capabilities of Amazon Nova Sonic, organizations can address these limitations and enable new interactive and personalized audio content formats that scale globally without traditional human resource constraints.
Solution overview
The Nova Sonic Live Podcast Generator demonstrates how to create natural conversations between AI hosts about any topic using the speech-to-speech model of Amazon Nova Sonic. Users enter a topic through a web interface, and the application generates a multi-round dialogue with alternating speakers streamed in real-time.
Key features
- Real-time streaming audio generation with low latency
- Natural back-and-forth dialogue across multiple conversational turns
- Stage-aware content filtering that removes duplicate audio
- Simple web interface with live conversation updates
- Concurrent user support through AsyncIO architecture
- Provides multiple voice personas for different use cases.
Prerequisites
To implement this solution, the following requirements must be met:
- AWS account with access to Amazon Bedrock and Amazon Nova 2 Sonic model
- Python 3.8 or later
- Flask web framework and AsyncIO
- AWS credentials are configured (access key, secret key, AWS Region)
- Development environment with pip package manager
Implementation details
For detailed code samples and complete implementation guidance, view in GitHub.
Architecture overview
The solution follows a Flask-based architecture with streaming and reactive event processing, designed to demonstrate the capabilities of Amazon Nova Sonic for proof-of-concept and educational purpose.
System architecture diagram
The following diagram illustrates the real-time streaming architecture:
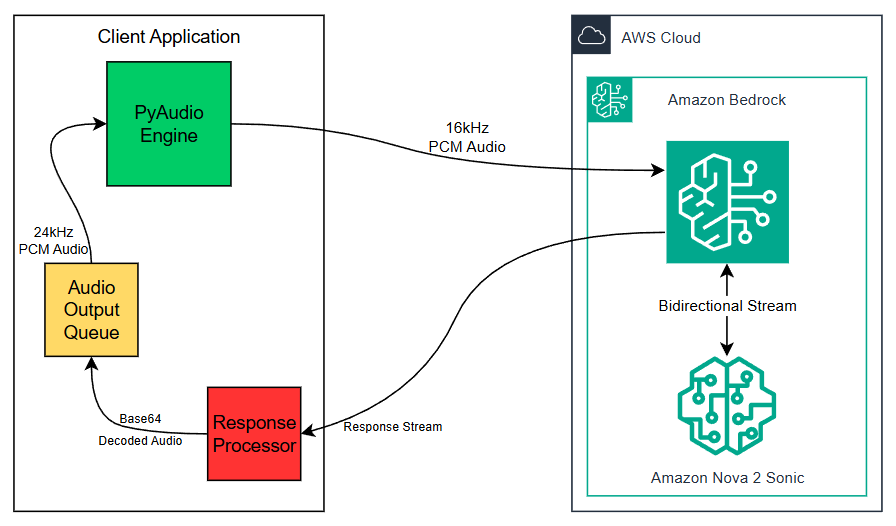
Architecture components
The architecture follows a layered approach with clear separation of concerns:
Client Application hosts three tightly coupled components that manage the full audio lifecycle:
- PyAudio Engine captures microphone input at 16kHz PCM and streams it to Amazon Bedrock. It also receives playback-ready audio from the Audio Output Queue at 24kHz PCM, handling speaker output in real time.
- Response Processor receives the raw response stream returned by Amazon Nova Sonic, decodes the Base64-encoded audio payload, and forwards the decoded audio to the Audio Output Queue.
- Audio Output Queue acts as a buffer between the Response Processor and the PyAudio Engine, absorbing variable-latency responses and ensuring smooth, uninterrupted audio playback at 24kHz PCM.
AWS Cloud – all model communication runs through Amazon Bedrock, which brokers a bidirectional event stream with Amazon Nova Sonic:
- Amazon Bedrock receives the outbound 16kHz PCM audio stream from the PyAudio Engine and routes it to the model. It also carries the model’s response stream back to the client.
- Amazon Nova Sonic receives the audio input through the bidirectional stream, performs real-time speech-to-speech inference, and returns a response stream containing synthesized audio encoded as Base64 PCM at 24kHz.
Production Architecture Note: This implementation uses Flask with PyAudio for demonstration purposes. PyAudio does not provide built-in echo cancellation and is best suited for server-side audio playback. For production web-based client applications, JavaScript-based audio libraries (Web Audio API) or WebRTC are recommended for browser-native audio handling with better echo cancellation and lower latency. See the GitHub repository for production architecture patterns.
Key technical innovations
Amazon Bedrock integration
At the heart of the system is the BedrockStreamManager, a custom component that manages persistent connections to the Amazon Nova 2 Sonic model. This manager handles the complexities of streaming API interactions, including initialization, message sending, and response processing. AWS credentials that are configured through environment variables maintains secure access to the foundation model (FM). The full code is in the GitHub Repository
Reactive streaming pipeline
The application employs RxPy (Reactive Extensions for Python) to implement an observable pattern for handling real-time data streams. This reactive architecture processes audio chunks and text tokens as they arrive from Amazon Nova Sonic, rather than waiting for complete responses.
The output_subject in the BedrockStreamManager acts as the central event bus, so multiple subscribers can react to streaming events simultaneously. This design choice reduces latency and improves the user experience by providing immediate feedback.
Stage-aware content filtering
One of the key technical innovations in this implementation is the stage-aware filtering mechanism. Amazon Nova 2 Sonic generates content in multiple stages: SPECULATIVE (preliminary) and FINAL (polished). The application implements an intelligent filtering logic that monitors contentStart events for generation stage metadata. It captures only FINAL stage content to remove duplicate or preliminary audio, and prevents audio artifacts for clean, natural-sounding output.
The filtering operates at three levels:
- Interrupted Content Filter – Removes canceled content by checking for interruption markers.
- Text Deduplication – Filters exact duplicate text across SPECULATIVE and FINAL stages.
- Audio Hash Deduplication – Filters duplicate audio chunks using hash fingerprinting.
This filtering happens in real-time within the capture callback function, which subscribes to the output stream and selectively processes events based on generation stage.
Note: The code snippets shown are simplified for clarity. The is_final_stage variable must be defined in the enclosing scope. See the GitHub repository for complete, production-ready implementations.
Conversation management
The system implements a turn-based conversation model with multiple rounds of dialogue. Each turn follows a consistent pattern for natural conversation flow:
- Conversation History – The application maintains conversation context through speaker-specific variables, so each speaker can reference what was previously said.
- Dynamic Prompt Generation – Prompts are constructed dynamically based on speaker role and conversation contex, for example, Matthew (host) introduces topics and asks follow-up questions, while Tiffany (expert) provides informed responses.
- Fresh Stream Per Turn – The application creates a fresh
BedrockStreamManagerinstance for each speaker turn, preventing state contamination between turns for clean audio streams.
Asynchronous execution model
To handle the blocking nature of audio playback and model API calls, the application creates a new asyncio event loop for each podcast generation request. This way, multiple users can generate podcasts simultaneously without blocking each other. The loop manages stream initialization, prompt sending, audio playback coordination, and cleanup, supporting concurrent usage while maintaining clean separation between user sessions.
Data flow overview
The system follows a streamlined flow from user input to audio output. Users enter a topic, the backend orchestrates conversation turns with dynamic prompt generation, Amazon Nova 2 Sonic generates speech responses through a streaming API, and stage-aware filtering makes sure that only polished FINAL content reaches the audio pipeline for playback.
For detailed code samples and complete implementation guidance, view in GitHub.
Use cases
The Amazon Nova 2 Sonic architecture enables automated, interactive audio content creation across multiple industries. By orchestrating conversational AI instances in dialogue, organizations can generate engaging, natural-sounding content at scale.
Interactive learning and knowledge sharing
Organizations struggle to create engaging content that helps people learn and retain information, whether for student education or employee training. Amazon Nova 2 Sonic instances can simulate classroom discussions or Socratic dialogues, with one instance posing questions while the other provides explanations and examples.
For educational institutions, this creates dynamic learning experiences that accommodate different learning styles and paces. For enterprises, it transforms internal communications (policies, procedures, organizational changes) into conversational formats that employees can consume while multitasking. Integration with Retrieval Augmented Generation (RAG) and Amazon Bedrock Knowledge Bases keeps content current and aligned with curriculum or organizational requirements, while the conversational format increases information retention and reduces follow-up questions.
Multilingual content localization
Global organizations need consistent messaging across markets while respecting cultural nuances. The Amazon Nova Sonic support for English, French, Italian, German, Spanish, Portuguese, and Hindi enables creation of localized audio content with native-sounding conversations. The model can generate market-specific discussions that adapt language, cultural references, and communication styles, going beyond simple translation to produce culturally relevant content that resonates with local audiences.
The polyglot voice capabilities – individual voices that can switch between languages within the same conversation – enable advanced code-switching capabilities that handle mixed-language sentences naturally. This is particularly valuable for multilingual customer support and global team collaboration.
Product commentary and reviews
Ecommerce platforms need engaging ways to help customers understand complex products. Amazon Nova 2 Sonic instances can generate conversational product reviews, with one asking common customer questions while the other provides answers based on specifications, user reviews, and technical documentation. This creates accessible content that helps customers evaluate products through natural dialogue, with integration to product catalogs ensuring accuracy.
Thought leadership and industry analysis
Professional services firms need to establish thought leadership through regular content but producing analysis requires significant time investment. Amazon Nova 2 Sonic instances can engage in expert-level discussions about industry trends or market analysis, with one challenging assumptions while the other defends positions with data. This allows organizations to repurpose existing research into accessible audio content that reaches busy executives who prefer audio formats.
Performance characteristics
- Latency: Low-latency streaming with immediate audio playback
- Podcast Duration: Flexible duration based on conversational turns (typically 2–5 minutes)
- Concurrent Users: Supports multiple simultaneous podcast generations through AsyncIO
- Audio Quality: Professional-grade speech synthesis with natural intonation and pacing
- Language Support: English, French, Italian, German, Spanish, Portuguese, and Hindi
- Context Window: Up to 1M tokens for extended conversation context
Conclusion
Amazon Nova 2 Sonic is a state-of-the-art speech understanding and generation model that enables natural, human-like conversational AI experiences. The architecture outlined in this post provides a practical foundation for building conversational AI applications. Whether streamlining customer support, creating educational content, or generating thought leadership materials, the patterns demonstrated here apply across use cases.
With expanded language support, polyglot voice capabilities, enhanced telephony integration, and cross-modal interaction, Amazon Nova 2 Sonic provides organizations with tools for building global, voice-first applications at scale.
To get started with building with Amazon Nova Sonic, visit the Amazon Nova product page. For comprehensive documentation, explore the Amazon Nova 2 Sonic User Guide.
Learn more
- Amazon Nova 2 Sonic Product Page
- Amazon Bedrock Documentation
- Amazon Nova 2 Sonic User Guide
- AWS Blog: Introducing Amazon Nova Sonic
- GitHub Repository: Official AWS samples