Building a text-to-SQL solution using Amazon Bedrock can alleviate one of the most persistent bottlenecks in data-driven organizations: the delay between asking a business question and getting a clear, data-backed answer. You might be familiar with the challenge of navigating competing priorities when your one-time question is waiting in the queue behind higher-impact work. A text-to-SQL solution augments your existing team—business users self-serve routine analytical questions, freeing up technical capacity across the organization for complex, high-value initiatives. Questions like “What is our year-over-year revenue growth by customer segment?” become accessible to anyone, without creating an additional workload for technical teams.
Many organizations find that accessing data insights remains a significant bottleneck in business decision-making processes. The traditional approach requires either learning SQL syntax, waiting for technical resources, or settling for pre-built dashboards that might not answer your specific questions.
In this post, we show you how to build a natural text-to-SQL solution using Amazon Bedrock that transforms business questions into database queries and returns actionable answers. The model returns not only raw SQL, but executed results synthesized into clear, natural language narratives in seconds rather than hours. We walk you through the architecture, implementation strategies, and lessons learned from deploying this solution at scale. By the end, you will understand how to create your own text-to-SQL system that bridges the gap between business questions and data accessibility.
Why traditional business intelligence falls short
It’s worth noting that tools like Amazon Quick already address many self-service analytics needs effectively, including natural language querying of dashboards and automated insight generation. These tools are an excellent fit when your analytics requirements align with structured dashboards, curated datasets, and governed reporting workflows. A custom text-to-SQL solution becomes valuable when users must query across complex, multi-table schemas with deep organizational business logic, domain-specific terminology, and one-time questions beyond what pre-configured dashboard datasets support.
Building a text-to-SQL solution surfaces three fundamental challenges that drive the need beyond traditional Business Intelligence (BI) tools:
- The SQL expertise barrier blocks rapid analysis. Most business users lack the technical SQL knowledge needed to access complex data. Simple questions often require multi-table joins, temporal calculations, and hierarchical aggregations. This dependency creates bottlenecks where business users wait extended periods for custom reports, while analysts spend valuable time on repetitive query requests rather than strategic analysis.
- Even modern BI systems have flexibility boundaries. Modern BI tools have made significant strides in natural language querying and self-service analytics. However, these capabilities typically work best within pre-curated semantic layers, governed datasets, or pre-modeled dashboards. When business users need to explore beyond curated boundaries, one-time joins, on-the-fly organization-specific calculations, or querying raw warehouse tables outside the semantic layer, they still face constraints that require technical intervention. A custom text-to-SQL solution fills this gap by operating directly against your data warehouse schema with dynamically retrieved business context, rather than depending on pre-configured semantic models.
- Context and semantic understanding create translation gaps. Even with SQL access, translating business terminology into correct database queries proves to be challenging. Terms like attainment, pipeline, and forecast each have unique calculation logic, specific data source requirements, and business rules that vary across organizations. Understanding which tables to join, how metrics are defined, and which filters to apply requires deep institutional knowledge that isn’t readily accessible to most users.
When building your own solution, consider how your system will encode this deep business context (strategic principles, customer segmentation rules, and operational processes), so users can make faster, data-driven decisions without understanding complex database schemas or SQL syntax.
How it works: The experience
Before diving into architecture, here’s what the experience looks like from a user’s perspective.
A business user enters a question into a conversational interface asking something like, “How is revenue trending this year compared to last year across our top customer segments?” Behind the scenes, the system does the following in a matter of seconds:
- Understands the question. It determines whether this is a single-step lookup or a complex question that must be broken into parts. In this case, it recognizes that “revenue trending,” “year-over-year comparison,” and “top customer segments” each require distinct data retrieval steps.
- Retrieves business context. The system searches a knowledge graph that encodes your organization’s specific metric definitions, business terminology, table relationships, and data rules. It knows what revenue means in your environment, which tables contain it, and how customer segment is defined.
- Generates and validates SQL. The system produces a structured SQL query, validates it for correctness and safety using deterministic checks, and executes it against your data warehouse. If validation catches an issue, it automatically revises and retries without requiring human intervention.
- Synthesizes the answer. Raw query results are translated back into a natural language narrative with supporting data, giving users both the insight and the transparency to trust it.
The result is that business users get answers to complex analytical questions in seconds to minutes, with full visibility into the underlying logic. Analysts are relieved from repetitive query work to focus on higher-value strategic analysis.
Solution overview
To deliver this experience, the solution combines three core capabilities:
- Foundation models (FMs) in Amazon Bedrock for natural language understanding and SQL generation
- Graph Retrieval-Augmented Generation (GraphRAG) for business context retrieval
- High-performance data warehouses for fast query execution.
Amazon Bedrock plays a central role in this architecture by providing both the large language model (LLM) inference layer and the agent orchestration runtime. Amazon Bedrock offers access to a broad selection of FMs, so teams can choose and swap models based on evolving performance, cost, and latency requirements without re-architecting the system.
As shown in the architecture diagram,
- Amazon Bedrock AgentCore Runtime serves as the central orchestration layer, hosting a supervisor Agent that coordinates the end-to-end workflow. It routes user questions, invoking the GraphRAG Search Tool for context retrieval, enforcing Row-Level Security, triggering SQL generation and validation, and executing queries against a database (Amazon Redshift). The runtime supports multiple entry points, including MCP and HTTP protocols, enabling integration with both embedded analytics surfaces like AWS Quick Sight and custom web interfaces.
- Amazon Bedrock AgentCore also provides built-in observability, feeding agent execution traces and performance metrics into Amazon CloudWatch for monitoring, debugging, and continuous optimization. This managed runtime alleviates the undifferentiated heavy lifting of building custom agent infrastructure, so teams can focus on business logic, prompt tuning, and domain knowledge enrichment.
The following diagram illustrates how this workflow operates:
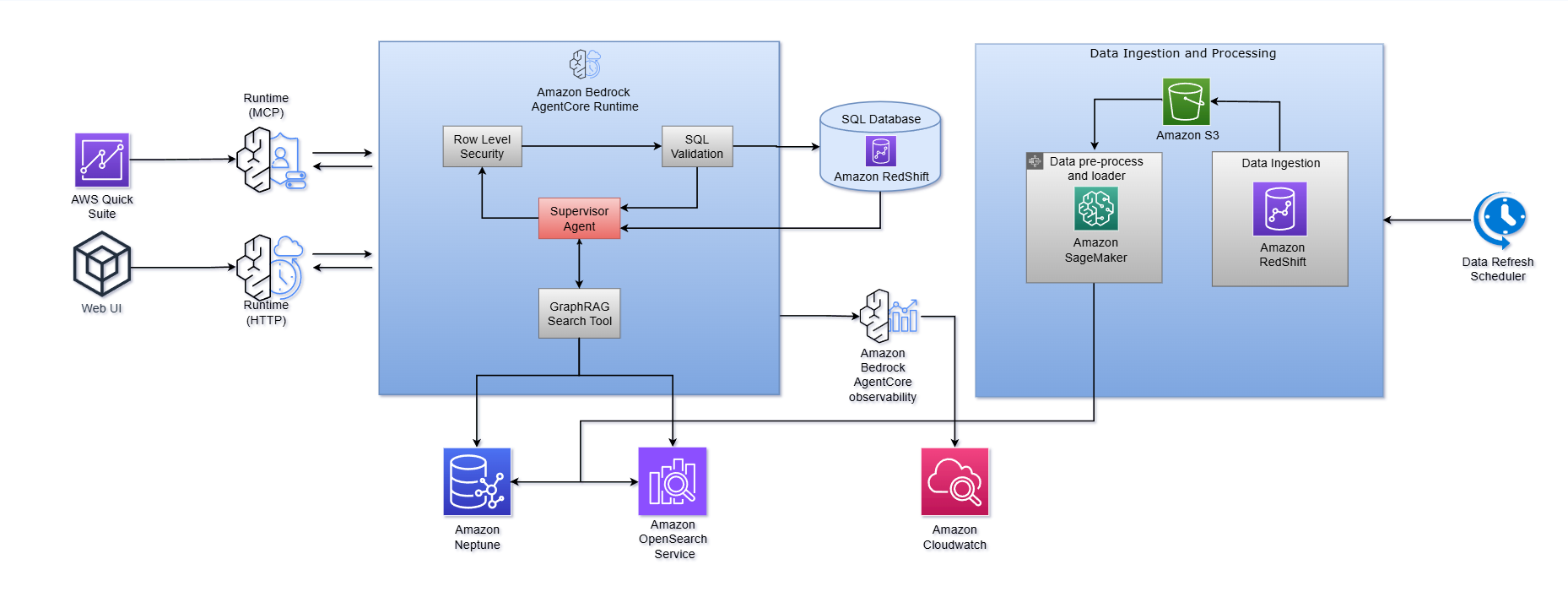
The architecture operates as an orchestrated multi-agent system with five key stages:
Stage 1: Question analysis and decomposition
When a question arrives, the question processor first classifies it. Straightforward, atomic, fact-based questions like “What was total revenue in Q4?”, are routed directly to the data retrieval pipeline. Complex or multi-part questions are decomposed into self-contained, independent subquestions that can be processed in parallel by separate agent teams. This decomposition step is what allows the system to handle sophisticated analytical questions that span multiple data domains, time periods, or business dimensions.
Stage 2: Knowledge graph and GraphRAG context retrieval
This is where the system solves the context barrier, and it’s the most critical differentiator from naive text-to-SQL approaches.
A knowledge graph built on Amazon Neptune and Amazon OpenSearch Service serves as the semantic foundation. It stores your organization’s table ontology and captures the relationships between business entities, metrics, terminology, and organizational hierarchies. Crucially, this graph is enriched with domain knowledge from table owners and subject matter experts for business-specific descriptions, metric definitions, terminology mappings, and classification tags loaded from structured configuration files.
When the system processes a question, it performs a lightweight GraphRAG search that works in three phases:
- Vector search (using Amazon OpenSearch Service): Finds semantically relevant column values, column names, and table descriptions that match the concepts in the user’s question.
- Graph traversal (using Amazon Neptune): Follows the relationships in the knowledge graph, from matched values to their parent columns to their parent tables, to build a complete picture of which data assets are relevant and how they connect.
- Relevance scoring and filtering: Ranks and structures the retrieved context so the SQL generator receives precisely the information it needs, the right tables, the right columns, the right join paths, and the right business logic.
The knowledge graph and its associated data are refreshed regularly to reflect schema changes, new tables, and evolving business definitions. The richer this contextual layer, the more accurate the downstream SQL generation becomes.
Stage 3: Structured SQL generation and validation
The system uses the function calling capabilities of Amazon Bedrock to produce SQL queries as structured data. This enforces strict output formats, alleviates the need for fragile post-processing or complex regular expressions, and significantly improves reliability.
Generated queries then pass through deterministic SQL validators operating at the Abstract Syntax Tree (AST) level. These validators proactively flag potentially risky operations, queries that are syntactically correct but semantically dangerous (for example, unbounded scans, missing filters, incorrect aggregation logic). When a validator flags an issue, it returns detailed feedback explaining the problem and suggesting a revision.
To further enhance robustness, the entire cycle is wrapped in a lightweight SQL generation agent that automatically iterates until it produces a valid, executable query or exhausts a configurable retry limit. This approach aims to deliver significantly better reliability than prompt engineering alone.
Stage 4: Test-time parallel compute
For ambiguous or complex questions, the system can generate multiple potential answers or reasoning paths simultaneously by submitting the same question to parallel agents. Results are synthesized through majority voting, selecting the most reliable output. This is particularly valuable for questions that can be interpreted in multiple ways, and it meaningfully improves both accuracy and robustness.
Stage 5: Response synthesis
Finally, raw query results including numbers, data frames, and execution logs are synthesized into natural language narratives that users receive as actionable answers. Full query transparency is maintained: users can inspect the generated SQL and underlying data at any time, building trust in the system’s outputs.
Key strategies for production-quality results
Architecture alone isn’t enough. The following strategies, learned from deploying this solution at scale, are essential for achieving the accuracy, safety, and responsiveness that production use demands.
Let end users shape the prompts
Even among experienced users, individuals often have differing default interpretations of ambiguous terms and varying expectations regarding responses to vague questions. We recommend building a customization interface, such as a web application, so table owners and designated power users can customize prompts within governed boundaries. Customizations should pass through validation guardrails that enforce content policies, restrict prompt injection attempts, and make sure modifications stay within approved templates and parameters. This helps prevent unrestricted free-text modifications while still incorporating domain knowledge and preferences into the system. This customization capability proves essential for achieving the nuanced understanding that different business domains require. Your solution should accommodate these variations rather than enforcing a one-size-fits-all approach.
Treat SQL validation as a safety-critical layer
Prompt engineering alone can’t remove errors that produce syntactically valid but semantically incorrect SQL. These errors are particularly dangerous because they return plausible-looking results that can silently erode user trust or drive incorrect decisions. Because SQL is a well-defined language, deterministic validators can catch a broad class of these errors before the query reaches your database. In internal testing, this validation layer effectively avoided serious errors in generated queries. Prioritize it as a non-negotiable safety mechanism.
Optimize aggressively for latency
Users accustomed to conversational AI expect near-instant responses. While retrieving live data and performing calculations inherently takes longer than answering from a static knowledge base, latency must still be actively managed as a first-class user experience concern. Performance analysis reveals that the workflow involves multiple steps, and the cumulative time across those steps represents the largest opportunity relative to SQL execution time alone.
To optimize, focus on:
- Parallel agent execution – Process multi-part questions concurrently rather than sequentially. This can dramatically reduce total time for complex queries.
- High-performance analytical storage – Use column-oriented databases that excel at the aggregation-heavy workloads typical in business intelligence.
- Token optimization – Minimize input and output tokens per agent interaction through prompt optimization and response format standardization. Reduce reliance on tool-calling agentic frameworks where each call forces the agent to re-ingest growing context.
With these optimizations, in our deployment, simple SQL queries are typically generated in approximately 3–5 seconds. Actual response times will vary based on factors such as data warehouse performance, query complexity, model selection, and knowledge graph size. We recommend benchmarking against your own environment to establish realistic latency targets for interactive business analysis.
Build security and governance in from the start
Implement Row-Level Security (RLS) integration so that users only ever see data they are authorized to access. The system maintains composite entitlement tables that enforce access control policies from your existing organizational systems. When a user submits a query, appropriate RLS filters are automatically injected into the generated SQL before execution. They’re transparent to the user, but rigorous in enforcement. Design this layer to uphold strict data governance standards without adding friction to the user experience.
Implementation results and impact
After you follow the architecture and strategies outlined in this post, a text-to-SQL solution can deliver significant improvements in data accessibility and analytical productivity:
- Speed improvements deliver answers to complex business questions in minutes, compared to hours or days with traditional approaches. Questions requiring multi-table joins, temporal calculations, and hierarchical aggregations that previously required custom SQL development become accessible through natural language.
- Analytical democratization helps non-technical business users across sales operations, financial planning, and executive leadership perform sophisticated data analysis without SQL expertise. This typically reduces analytical workload on data engineering teams, allowing them to focus on strategic initiatives rather than repetitive query requests.
- Complex query handling supports multi-dimensional revenue analysis with the following capabilities:
- automatic segmentation
- year-over-year and month-over-month trending with variance explanations
- customer intelligence at granular levels with usage patterns
- forecast variance analysis with target comparisons
- cross-functional benchmarking across time periods and business units
Looking forward
Text-to-SQL solutions powered by Amazon Bedrock represent a significant step forward in making data analytics accessible to business users. The multi-agent architecture using Amazon Bedrock Agents supports complex query decomposition and parallel processing, while knowledge graphs provide business context and semantic understanding. Together, these components deliver accurate, fast, and accessible analytics that empower business users to make data-driven decisions without technical barriers.
As you build your own solution, consider expanding knowledge graph coverage to additional business domains, optimizing response latency through advanced caching strategies, and integrating with more enterprise data sources. Amazon Bedrock Guardrails offer enhanced output validation and safety capabilities worth exploring, while Amazon Bedrock Flows provide sophisticated orchestration patterns for agentic workflows.
The FM flexibility, agent orchestration capabilities, and knowledge base integration available through Amazon Bedrock continue to evolve, making data analysis increasingly intuitive and powerful for business users across organizations.
To build your own text-to-SQL solution, explore the Amazon Bedrock User Guide, participate in an Amazon Bedrock Workshop, and review our guide on Building generative AI agents with Amazon Bedrock. For the latest developments, see What’s New with AWS.
Acknowledgments
We extend our sincere gratitude to our executive sponsors and mentors whose vision and guidance made this initiative possible: Aizaz Manzar, Director of AWS Global Sales; Ali Imam, Head of Startup Segment; and Akhand Singh, Head of Data Engineering.