This post is cowritten by Paul Burchard and Igor Halperin from Artificial Genius.
The proliferation of large language models (LLMs) presents a significant paradox for highly regulated industries like financial services and healthcare. The ability of these models to process complex, unstructured information offers transformative potential for analytics, compliance, and risk management. However, their inherent probabilistic nature leads to hallucinations, plausible but factually incorrect information.
In sectors governed by stringent requirements for auditability and accuracy, the non-deterministic behavior of standard generative AI is a barrier to adoption in mission-critical systems. For a bank or a hospital, determinism isn’t only a goal; the outcomes must be accurate, relevant, and reproducible.
In this post, we’re excited to showcase how AWS ISV Partner Artificial Genius is using Amazon SageMaker AI and Amazon Nova to solve this challenge. By introducing a third generation of language models, they’re delivering a solution that is probabilistic on input but deterministic on output, helping to enable safe, enterprise-grade adoption.
To understand the solution, let’s look at how AI has evolved:
- First generation (1950s): Researchers used symbolic logic to build deterministic, rule-based models. While safe, these models lacked fluency and could not scale.
- Second generation (1980s–present): The shift to probabilistic models (culminating in the Transformer architecture) unlocked incredible fluency. However, because these models predict the next token based on probability, they suffer from unbounded failure modes (hallucinations) that are difficult to engineer away.
- Third generation (the Artificial Genius approach): Rather than a new generation that replaces the old, we’re moving from the rigidity of symbolic logic and the unpredictability of probabilistic models toward a hybrid architecture. This approach uses the generative power of Amazon Nova to understand context but applies a deterministic layer to verify and produce output. It’s the convergence of fluency and factuality.
The solution: A paradoxical approach to generation
It’s mathematically difficult to prevent standard generative models from hallucinating because the extrapolative, generative process itself causes errors. Artificial Genius addresses this by using the model strictly non-generatively. In this paradigm, the vast probability information learned by the model is used only interpolatively on the input. This allows the model to comprehend the innumerable ways a piece of information or a question can be expressed without relying on probability to generate the answer. To create this third-generation capability, Artificial Genius uses SageMaker AI to perform a specific form of instruction tuning on Amazon Nova base models.
This patented method effectively removes the output probabilities. While standard solutions attempt to ensure determinism by lowering the temperature to zero (which often fails to address the core hallucination issue), Artificial Genius post-trains the model to tilt log-probabilities of next-token predictions toward absolute ones or zeros. This fine-tuning forces the model to follow a single system instruction: don’t make up answers that don’t exist.
This creates a mathematical loophole where the model retains its genius-level understanding of data but operates with the safety profile required for finance and healthcare.
Going beyond RAG
Retrieval Augmented Generation (RAG) is frequently cited as the solution to accuracy, but it remains a generative process and creates fixed vector embeddings that might not be relevant to subsequent queries. The third-generation approach improves upon RAG by effectively embedding the input text and the user query into a unified embedding. This helps ensure that the data processing is inherently relevant to the specific question asked, delivering higher fidelity and relevance than standard vector retrieval methods.
Delivering value using agentic workflows
To help enterprises maximize the value of their unstructured data, Artificial Genius packages this model into an industry-standard agentic client-server platform, available through AWS Marketplace.
Unlike second-generation agents, which risk compounding errors when strung together in workflows, the inherent reliability of this third-generation model allows for complex, high-fidelity automation. The prompts used to create these workflows follow the structure of a product requirements document (PRD). Through this structure, domain experts—who might not be AI engineers—can formulate queries in natural language while maintaining strict control over the output.
The product additionally offers free-form prompting of the workflow specification. For this purpose, the Amazon Nova Premier model, which is especially capable of translating free-form prompts into PRD format, is used. Although Nova Premier is a generative model, which requires a human-in-the-loop to check its output, this is the only human checkpoint in the agentic workflow.
Defining the non-generative query
The core mathematical loophole employed here is using a generative model strictly non-generatively. This means the model doesn’t use probabilities to guess the next token of an answer, but rather extracts or verifies information based solely on the input context. While short answers (such as dates or names) are obviously non-generative, it’s also possible to output long sequences deterministically. For example, asking for a direct quote from a document to justify a previous answer is a non-generative task. The following are examples of how Artificial Genius structures these interactions (the system prompt containing anti-hallucination instructions isn’t shown in these JSON turns):
Answerable, non-generative short answer:
Answerable, non-generative, long-answer, follow-up question
These are only illustrative examples. The third-generation language model products will be delivered with recipes to assist with understanding how to construct non-generative queries to meet all practical natural language processing needs. With this understanding, let’s explore the technical implementation of building a non-generative fine-tuning pipeline using Amazon Nova on SageMaker AI.
AWS Reference Architecture
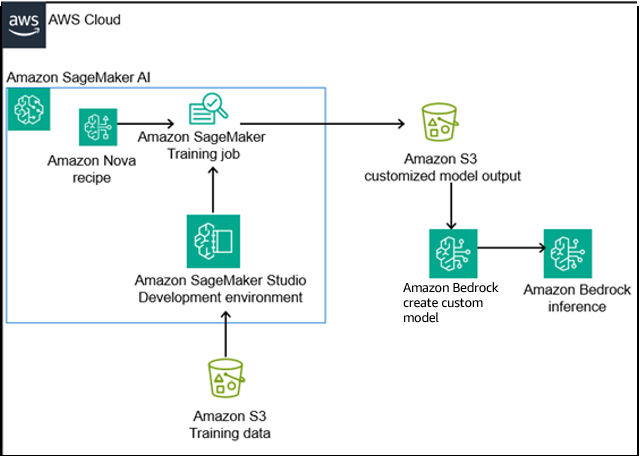
The architecture shown in the preceding diagram uses a streamlined approach to customizing foundation models. It uses SageMaker Training jobs for model training and Amazon Bedrock for deployment.
- Data storage: Training data (synthetic Q&A) is stored in Amazon Simple Storage Service (Amazon S3).
- Training: SageMaker Training jobs provision compute resources to fine tune the Nova base model using the instruction tuning with supervised fine-tuning (SFT) method.
- Deployment: The fine-tuned model is imported into Amazon Bedrock using the create custom model feature.
- Inference: Applications interact with the model through Amazon Bedrock endpoints using the on-demand inference feature of Amazon Bedrock to create a custom model, helping to ensure a secure, scalable loop.
This design separates development concerns from production inference while maintaining clear data lineage—essential for audit trails in financial services.
Technical implementation: A step-by-step guide for non-generative fine-tuning
As indicated previously, the construction of a third-generation language model involves the following steps:
- It starts with a second-generation foundation model. The first task is to select a good base model. As you will see, the Amazon Nova family includes ideal candidates to serve as this base.
- The base model must be post-trained to follow a single system instruction: Do not make up answers. Of course, many people have tried this before, but now we understand from mathematics that this is only possible for non-generative questions. So, it’s important to understand, on a practical level, what types of questions are generative and which are non-generative.
- Because the post-training gives the language model a general-purpose capability, its success is critically dependent on the construction of a high-quality, highly diverse data set that fully exercises this general capability. Artificial Genius has produced a proprietary synthetic, non-generative Q&A generator, that includes both answerable and unanswerable questions. This synthetic data generator will be the foundation of any customized third-generation language model builds produced by enterprise customers.
- Finally, SageMaker AI offers a cost-effective and capable post-training platform that enables the efficient production of final models, which will be explored in detail.
Let’s go through these steps in more detail.
Choosing the right foundation model
In building a third-generation language model, we want to focus on reliability and safety. Some foundation models, built for different use cases, have other capabilities that distract and make them less suitable for non-generative use.
An important example is that some foundation models are optimized for use as chat assistants, which can make it difficult to persuade them to provide concise instead of verbose and discursive answers. Correcting such a tendency can require additional post-training beyond following the non-hallucination instruction. The Amazon Nova family of models is designed for a strong balance of performance, cost-efficiency, and speed, making them ideal candidates for enterprise applications, and within the Nova family, the Nova Lite model is naturally inclined to provide crisp and concise answers. Nova Lite therefore makes an ideal base model for this purpose.
Another relevant recent development is the addition of post-inference features to second-generation language models, often based on chain of thought (CoT) or on reinforcement learning methods. These features, while they have utility, interfere with the creation of a non-generative third-generation model. For example, when applying this methodology to the DeepSeek/Llama3 model, which includes chain of thought, it was necessary to perform prompt injection by including the model’s internal </think> tokens directly in the training data to shut off these extra features. Fortunately, Amazon Nova Lite doesn’t have any post-inference features.
Designing a post-training instruction-following task
Post-training, such as SFT, can then be applied to the base model, to train it to follow an anti-hallucination instruction included in the system prompt. This instruction could be, for example: If the Question cannot be answered from the Document, then answer “Unknown” instead.
If this sounds obvious—it has been tried many times before—remember that this seemingly obvious idea only works in combination with the non-obvious, counterintuitive mathematical principle of using the generative model in a strictly non-generative way.
Building high quality, anti-hallucinatory post-training data
Artificial Genius has created a proprietary synthetic, non-generative Q&A generator that’s designed to exercise the model’s ability to correctly answer or refuse to answer a great variety of non-generative questions. Artificial Genius’s synthetic Q&A generator builds on previous research into synthetic generation of Q&A for the financial domain, but focuses on producing the greatest variety of purely non-generative Q&A and expanding by multiples the dimensions of diversity of the input text, questions, and answers. Constructing a suitable synthetic Q&A generator for this task is a significant engineering endeavor. But with Artificial Genius’s synthetic Q&A generator as a base, customer-specific post-training tasks can be combined with it to create customized, third-generation language models.
Overcoming the post inference CoT
Chain-of-thought (CoT) is a prompting technique that improves LLM performance on complex reasoning tasks by encouraging the model to generate intermediate, step-by-step reasoning before arriving at a final answer. While often beneficial, we discovered that an innate CoT-like behavior in the initial deepseek-ai/DeepSeek-R1-Distill-Llama-8B model was counterproductive. It generated verbose, non-deterministic reasoning steps instead of the required concise, factual outputs, and it caused the model to attempt lengthy excursions of reasoning to answer every question, even those that were unanswerable. To solve this, the team developed a novel prompt meta-injection technique. This approach involves reformatting the training data to preemptively terminate the model’s CoT process. Using the same JSON format as the previous examples, the data was structured as follows:
By injecting the </think> token—intended only for internal use by the model—immediately before the ground-truth answer in every training example, the model learned to associate the completion of its internal process directly with the start of the final, correct output. This effectively short-circuited the unwanted verbose reasoning at inference time, forcing the model to produce only the desired deterministic answer.
This technique is a powerful example of using data format as a tool to control and shape a model’s innate behavior.
Fine tuning Amazon Nova for peak performance
The SFT technique chosen for the non-hallucination task is Low-Rank Adaptation (LoRA) because it most faithfully preserves the language comprehension of a foundation model, merely placing a parameterized adapter on top. Other fine-tuning methods, which directly change parameters of the base model, risk degrading this capability. As is well known in the research literature on SFT, the biggest hurdle to overcome is avoiding overfitting. There are many techniques to avoid overfitting with LoRA-based SFT, which are supported by the fine-tuning recipes provided within SageMaker AI:
- Regularization: This is the most general method to prevent overfitting. The SageMaker recipes for LoRA SFT have support for one regularization method: LoRA dropout. The research literature suggests that the optimal value is about 50% dropout, and experiments confirm the optimality of that value.
- Parameter reduction: This is a brute force way of avoiding overfitting, but with the downside of risking underfitting instead. The SageMaker recipes for LoRA SFT support one parameter reduction method, reducing the LoRA rank by reducing the LoRA
alphaparameter. In this case, it doesn’t help to reduce this parameter because doing so underfits more than it reduces overfitting. Because our goal is to create a general-purpose capability, it’s best to keep the raw parameter count as high as possible, not reduce it. - Early stopping: Often the training will initially improve the validation error, but after some steps, it will start overfitting, with the training error going down but the validation error going back up. Although SageMaker AI doesn’t support automatic early stopping, you can perform it manually by checking the course of the validation error on a longer, overfitting training run, and then manually limiting the number of epochs to the point where the validation error is minimized. This can be accomplished using the time series of validation errors for each epoch returned by SageMaker AI.
- Increased quantity and diversity of training data: Because the objective is to train a general-purpose capability, that is, avoid hallucination, the greater the quantity and diversity of the training data, the less the model has a chance to overfit on the specific data it’s trained on. Because the training data is synthetically generated, combinatorial (that is, exponential) amounts of distinct training examples can be produced as needed. This last method is the most effective for this general-purpose task but requires careful construction of the synthetic data generator to help ensure the ability to scale to sufficient quantity and diversity of training data.
Putting together all of these techniques—50% LoRA dropout regularization, maximizing instead of minimizing the number of LoRA parameter, to avoid unintentional underfitting, manual early stopping based on tracking the validation metrics from a longer run, and increasing the size of the synthetic training dataset to 30,000 examples—we can obtain a hallucination rate of 0.03% for the Artificial Genius custom version of Nova Lite.
To help you see the impact of various hyperparameter choices, which might be helpful for other customers using SageMaker for fine-tuning, the following tables shows some quantitative results from exploring the hyperparameter space for this task. The important hyperparameter choices in each case are highlighted in bold. The same 10,000-example test dataset was used, independent of the number of training examples, to measure the real final hallucination rates in cases where that number is shown. For the other cases, which were overfitting by stopping too late, only the validation error checkpoints are shown.
| LoRA dropout | LoRA alpha | Training epochs (or validation checkpoints) | Training examples | LoRA learning rate | Hallucination rate (or validation errors) |
| 50% | 128 | 3 | 10,000 | 32 | 7.5% |
| 50% | 192 | 2–4 | 10,000 | 28 | 1.0%–3.9% |
| 50% | 32 | 2–4 | 10,000 | 24 | 1.5%–2.6% |
| 1% | 32 | 2–4 | 10,000 | 24 | 1.6%–4.0% |
| 50% | 192 | 2 | 2,500 | 28 | 3.3% |
| 50% | 192 | 2 | 10,000 | 28 | 0.17% |
| 50% | 192 | 2 | 30,000 | 16 | 0.03% |
It’s apparent from these empirical results that the quantity and diversity of the training data was the most important factor to overcome overfitting, coupled with early stopping.
How to set up and run fine-tuning jobs on SageMaker
AWS has resources that explain how to take advantage of SageMaker for fine tuning, such as the technical blog post, Advanced fine-tuning methods on Amazon SageMaker AI.
For enterprises interested in combining their domain-specific fine-tuning with Artificial Genius’s anti-hallucination technology, customized fine-tuning is available upon inquiry, in collaboration with AWS and Artificial Genius.
A quantitative analysis of performance and verifiability
The success of the non-generative fine tuning methodology was validated through a rigorous evaluation framework that produced clear, quantitative results.
The evaluation framework
A multi-faceted evaluation framework was established to measure performance against the project’s core objectives:
- Hallucination reduction: This was the primary metric, quantified by measuring the percentage of responses that contained fabricated information when the model was tested on a set of unanswerable questions.
- Complex inference capabilities: The model’s performance was assessed on its ability to handle correctly answering or refusing to answer a variety of non-generative questions about a variety of input text, including complex questions requiring the comprehension and combination of information from multiple, distant parts of the input text.
- Metrics for regulated environments: The hallucination rate is unambiguous and straightforward to calculate—it’s the percentage of unanswerable questions that were answered with anything except the instructed non-answer. If desired, this hallucination rate can be interpreted as an F1 or ROUGE score.
Lessons learned and insights
Here are several key insights that serve as best practices for implementing trustworthy AI in regulated settings:
- Data engineering is paramount: The success of highly specialized fine-tuning is overwhelmingly dependent on the quality and intelligent design of the training data to prevent overfitting. The strategic inclusion of negative examples (unanswerable questions) is a critical and highly effective technique for mitigating hallucinations.
- Balance capability with control: For enterprise AI, the primary objective is often to intelligently constrain a model’s vast capabilities to help ensure reliability, rather than unleashing its full generative potential. Determinism and auditability are features to be engineered, not assumed.
- Embrace an iterative approach: Applied machine learning development is an iterative process. The team began with one model, identified a behavioral flaw (unwanted CoT), engineered a data-centric solution (meta-injection), and ultimately benchmarked and selected a superior base model (Amazon Nova). This highlights the need for flexibility and empirical validation at each stage of development.
Conclusion: The path forward for trustworthy AI in finance
The methodology detailed in this article represents a viable, data-efficient framework for creating deterministic, non-hallucinating LLMs for critical enterprise tasks. By using non-generative fine-tuning on powerful foundation models like Amazon Nova within Amazon SageMaker Training Jobs, organizations can engineer AI systems that meet the stringent demands of accuracy, auditability, and reliability. This work provides for a solution for more than financial services; it offers a transferable blueprint for any regulated industry—including legal, healthcare, and insurance—where AI-driven insights must be verifiably true and fully traceable. The path forward involves scaling this solution to a wider range of use cases, exploring more complex non-generative task types, and investigating techniques like model distillation to create highly optimized, cost-effective worker models to serve as the brains for agentic workloads. By prioritizing engineered trust over unconstrained generation, this approach paves the way for the responsible and impactful adoption of AI in the world’s most critical sectors.
Contribution: Special thanks to Ilan Gleiser who was a Principal GenAI Specialist at AWS WWSO Frameworks team and helped us with this use case.