This post is cowritten with Hammad Mian and Joonas Kukkonen from Bark.com.
When scaling video content creation, many companies face the challenge of maintaining quality while reducing production time. This post demonstrates how Bark.com and AWS collaborated to solve this problem, showing you a replicable approach for AI-powered content generation. Bark.com used Amazon SageMaker and Amazon Bedrock to transform their marketing content pipeline from weeks to hours.
Bark connects thousands of people each week with professional services, from landscaping to domiciliary care, across multiple categories. When Bark’s marketing team identified an opportunity to expand into mid-funnel social media advertising, they faced a scaling problem: effective social campaigns require high volumes of personalized creative content for rapid A/B testing, but their manual production workflow took weeks per campaign and couldn’t support multiple customer segment variations.
If you’re facing similar content scaling challenges, this architecture pattern can be a useful starting point. Working with the AWS Generative AI Innovation Center, Bark developed an AI-powered content generation solution that demonstrated a substantial reduction in production time in experimental trials while improving content quality scores. The collaboration targeted four objectives:
- Production time – Reduce from weeks to hours
- Personalization scale – Support multiple customer micro-segments per campaign
- Brand consistency – Maintain voice and visual identity across generated content
- Quality standards– Match professionally produced advertisements
In this post, we walk you through the technical architecture we built, the key design decisions that contributed to success, and the measurable results achieved, giving you a blueprint for implementing similar solutions.
Solution overview
Bark collaborated with the AWS Generative AI Innovation Center to develop a solution that could tackle these content scaling challenges. The team designed a system using AWS services and tailored AI models. The following diagram illustrates the solution architecture.
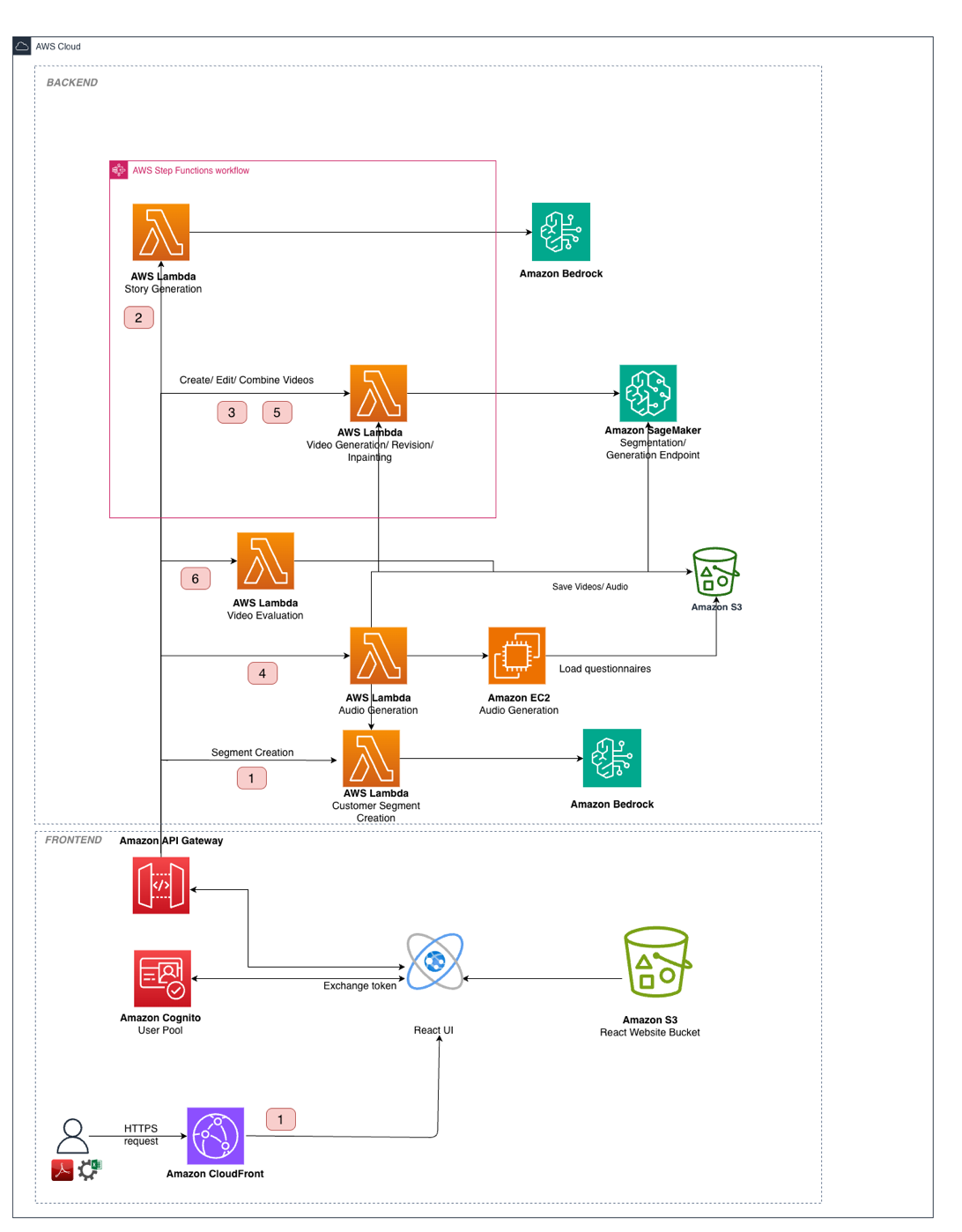
The solution architecture consists of the following integrated layers:
- Data and storage layer – Amazon Simple Storage Service (Amazon S3) stores assets including training data, generated video segments, reference images, and final outputs. Model artifacts and custom inference containers are stored in Amazon Elastic Container Registry (Amazon ECR).
- Processing layer – AWS Lambda orchestrates the multi-stage pipeline, with AWS Step Functions managing the workflow state across the seven-step generation process. Amazon Bedrock with Anthropic’s Claude Sonnet 3.7 handles text generation tasks, including customer segmentation, story generation, and quality evaluation.
- GPU compute layer – To serve Wan 2.1 Text2Video-14B reliably, we run a multi-GPU inference container that shards the model across eight GPUs on a single p4de.24xlarge SageMaker instance using tensor parallelism. TorchServe fronts the endpoint for request handling, and torchrun launches one worker process per GPU. We use Fully Sharded Data Parallel (FSDP) sharding—a technique for splitting the model components across GPUs—for the text encoder and the diffusion transformer to stay within GPU memory limits without offloading weights to CPU. Because video diffusion is long-running, the endpoint is tuned with an extended inference timeout and a longer container startup health-check window to accommodate model load time and help avoid premature restarts. Amazon Elastic Container Service (Amazon ECS) containers on GPU-enabled g5.2xlarge instances handle speech synthesis for narrator voice generation, scaling to zero during idle periods.
- User interface layer – A React frontend with Amazon Cognito authentication provides a video studio interface where marketing teams can review, edit, and approve generated content through natural language commands.
Creative ideation pipeline
Now that you understand the overall architecture, let’s examine how you can implement the creative ideation pipeline in your own environment. The pipeline transforms customer questionnaire data into production-ready storyboards through three stages.
Stage 1: Customer segment generation
The pipeline begins by analyzing Bark’s customer questionnaire data using Amazon Bedrock with Anthropic’s Claude Sonnet 3.7. The large language model (LLM) processes survey responses to identify distinct customer personas with structured attributes including demographics, motivations, pain points, and decision-making factors. For example, in the domiciliary care category, the system identified segments such as:
- The Overwhelmed Family Caregiver – Adults in their 40s–50s balancing work responsibilities with caring for aging parents, prioritizing reliability and trust
- The Independence-Focused Senior – Elderly individuals seeking to maintain autonomy while acknowledging the need for occasional assistance
Each segment profile is reviewed in the UI through a human-in-the-loop process and serves as input to subsequent creative ideation, creating advertisements that resonate with identified audience characteristics.
Stage 2: Creative brief generation
Given the business category and target segment, the system generates 4–6 creative concepts with varying degrees of abstraction—encouraging both literal and metaphorical approaches. We configure the model with high temperature sampling (0.8–1) to encourage divergent thinking. The model employs chain-of-thought reasoning, explicitly evaluating concept relevance, engagement potential, and entertainment value before generating briefs. This produces diverse narrative approaches to the same commercial objective, such as straightforward testimonial formats or emotionally resonant metaphorical stories.
Stage 3: Storyboard refinement
The final stage transforms generic creative briefs into segment-specific storyboards. A stochastic feature sampling mechanism—which randomly determines which attributes to highlight—identifies which customer segment attributes to emphasize, maintaining diversity while addressing specific motivations and pain points. The system performs explicit brief-to-segment matching through prompted reasoning before generating the final storyboard with complete audiovisual specifications—including scene descriptions, camera directions, narration text, and timing. Human review at this stage confirms brand alignment before production begins.
Maintaining visual consistency across scenes
A 30-second advertisement contains 4–6 distinct scenes, which are best generated individually. Without careful orchestration, AI models exhibit semantic drift—characters change appearance, backgrounds shift unexpectedly, and brand elements become inconsistent. Our solution implements a two-tier consistency framework.
Semantic consistency
You can transform creative briefs into video prompts through a three-stage process:
- Element extraction – An LLM analyzes the storyboard to identify atomic decor elements—actors, props, objects, and locations—and flags those requiring consistency across scenes.
- Blueprint generation – For each recurring element, the system generates detailed specification blueprints, establishing canonical visual representations.
- Prompt transformation – High-level scene descriptions are transformed into detailed video generation prompts, incorporating both the original creative brief (for narrative adherence) and standardized decor specifications (for visual consistency).
Visual consistency
Although semantic consistency through detailed prompts significantly reduces drift, video generation models still exhibit interpretive latitude even under identical prompt specifications. To address this limitation, we implement a reference image extraction and propagation pipeline, as illustrated in the following diagram.
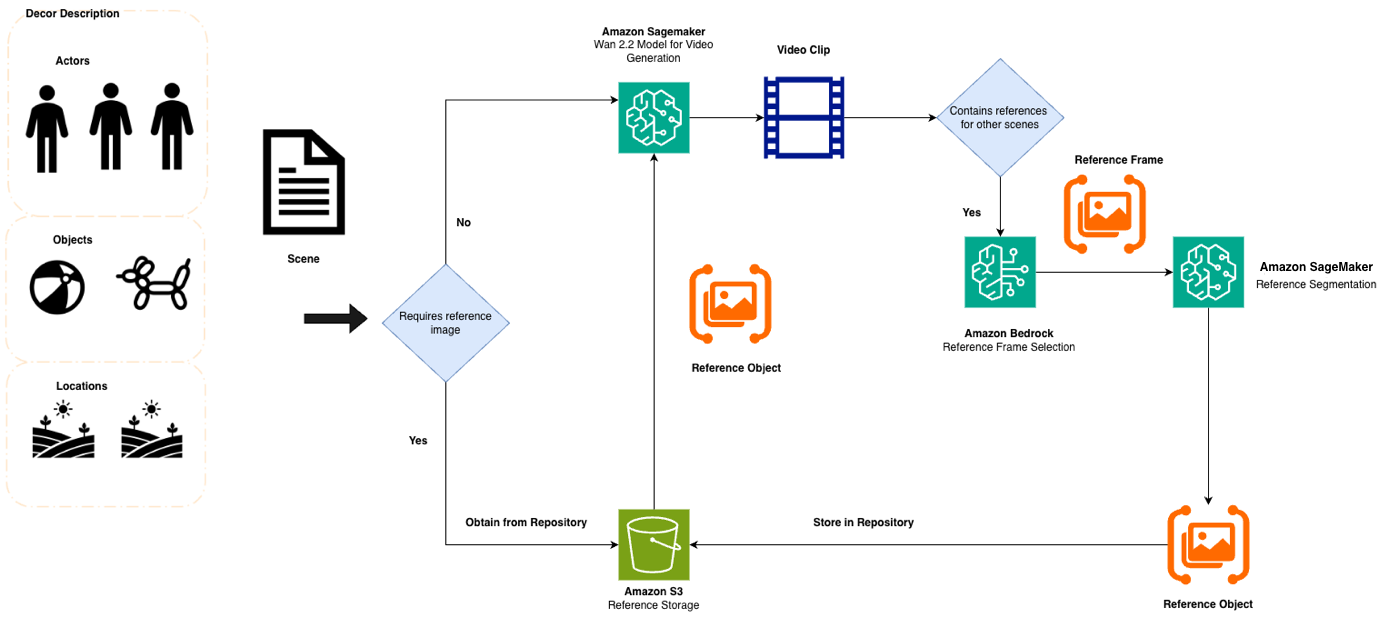
The pipeline consists of the following stages:
- Optimal frame identification – Amazon Nova Premier analyzes generated scenes to identify frames where target elements appear most clearly.
- Element segmentation – The open-source Segment Anything Model, deployed on Amazon ECS, isolates target elements from backgrounds.
- Reference propagation – Extracted reference images are fed to subsequent video generation calls using Wan 2.2’s reference-to-video capabilities.
This dual-constraint approach—combining semantic specification through detailed prompts with visual specification through reference images—creates a robust consistency framework that we validated through systematic ablation studies.
The video generation pipeline
The pipeline orchestrates five modalities—text, image, video, audio, and overlay graphics—with strategic model selection based on scene requirements:
- Reference-to-video synthesis – Scenes requiring visual continuity use Wan 2.1 VACE- 14B with extracted reference images
- Text-to-video generation – Scenes introducing new elements use Wan 2.1 Text2Video-14B
A Step Functions workflow sequences generation to verify reference images are available before dependent scenes begin.
Speech synthesis and graphics
Speech synthesis uses Sesame AI Lab’s Conversational Speech Model on GPU-enabled ECS instances (g5.2xlarge). Voice cloning requires a 10-second reference sample of Bark’s brand narrator; the model extracts speaker embeddings that can be used to condition subsequent generation. Amazon ECS scales to zero during idle periods, alleviating costs outside active generation windows. In addition, text overlays and call-to-action graphics use template systems that support typographic consistency with Bark’s brand guidelines. These elements are composited during final assembly.
Quality evaluation loop
An LLM-as-a-judge evaluation loop in Lambda assesses each scene across three dimensions:
- Narrative adherence – Accuracy to storyboard description
- Visual quality – Absence of artifacts and inconsistencies
- Brand compliance – Alignment with brand guidelines
Scenes falling below configurable quality thresholds trigger automated regeneration while preserving visual reference elements. This iterative refinement continues until scenes meet quality standards or human review is requested.
Messaging consistent landing pages
Using generated videos and the customer segment as the base, we created an agentic system to generate personalized landing pages. We used a Strands agent to perform the following actions:
- Generate the TypeScript code for the page
- Take optimal screenshots from the video to include in the page (for the user to understand it’s related directly to the video ad they had viewed)
- Amend the wording and design to align with the customer segment
Results
We evaluated AI-generated content against Bark’s existing campaign library. The following table summarizes the results.
| Evaluation Dimension | AI-Generated Ads | Existing Campaign Library |
| Story Structure C Coherence | 6.9 ± 0.49 | 6.4 ± 0.74 |
| Originality C Engagement | 6.5 ± 1.23 | 5.2 ± 1.22 |
| Visual C Spatial Consistency | 6.9 ± 0.74 | 6.6 ± 0.75 |
Scores on a 10-point scale with 95% confidence intervals
The results demonstrate that AI-generated content achieved higher narrative coherence scores, validating the hierarchical scene planning approach. The 25% improvement in originality scores suggests the creative ideation pipeline successfully balances novelty with commercial viability. The reference image propagation system delivered measurably higher character and environment consistency than manual production.
End-to-end, the pipeline generates a 15–30 second ad in approximately 12–15 minutes on ml.p4d.24xlarge SageMaker instances; this includes orchestration (reference extraction/segmentation), automated quality checks, and regeneration loops—not just a single model call. Multi-GPU sharding (8-way tensor parallel) keeps per-scene generation in the seconds-to-a-few-minutes range by fitting the 14B model fully in GPU memory and accelerating the heavy attention/denoising compute. Running it behind a SageMaker real-time endpoint keeps the model warm between requests and helps avoid latency from repeated model loads, and long-inference timeouts and startup health checks reduce failures and retries for long-running diffusion calls.
Ablation study
To validate each architectural decision, we conducted systematic ablation studies. The following table summarizes the results.
| Configuration | Story Coherence | Engagement | Visual Consistency |
| Full system | 6.9 | 6.5 | 6.9 |
| Without reference image propagation | 7.5 | 4.8 | 6.7 |
| Without narrative element extraction | 7.6 | 4.5 | 6.4 |
| Without hierarchical scene planning | 7.0 | 4.5 | 6.5 |
The results reveal that removing reference image propagation significantly impacts engagement scores (from 6.5 to 4.8), indicating consistent character representation supports more sophisticated narrative development. Disabling narrative element extraction caused the most severe engagement degradation while slightly improving structural scores—suggesting structured narrative analysis supports creative risk-taking while maintaining coherent storylines.
What this means for your implementation
Based on our experience, the following are actionable guidelines for your own video generation projects:
- Human-in-the-loop is essential – Although the system automates the bulk of production time, human intervention at creative brief approval and final review confirms brand alignment.
- Reference image quality matters more than quantity – Our adaptive reference extraction system dynamically identifies optimal frames through multi-criteria assessment (visual clarity, lighting, element prominence). Poor reference images propagate errors throughout the video sequence.
- LLM-as-a-judge supports rapid iteration – Traditional video evaluation is expensive and slow. Using Anthropic’s Claude to evaluate generated content against structured criteria supported rapid experimentation with different generation approaches.
- Design for compound consistency challenges – Single-character consistency has been deeply researched; the harder problem is maintaining consistency of compound elements like furnished rooms where multiple visual attributes must coexist. Plan architecture around these complex cases.
Cleaning up
If you replicate this solution in your own environment, remember to delete resources when you’re done experimenting to avoid ongoing costs:
- Delete SageMaker endpoints.
- Remove S3 buckets containing generated assets.
- Terminate Amazon ECS services and task definitions.
- Delete Lambda functions and Step Functions state machines.
Conclusion
This collaboration establishes a replicable pattern for AI-assisted creative production using AWS services. The core architectural insight—combining semantic consistency through hierarchical prompt planning with visual consistency through reference image propagation—addresses fundamental challenges in multi-scene video generation that extend beyond advertising into various domains requiring coherent, extended narratives.For Bark, the solution, under business evaluation, has the potential to support rapid experimentation with personalized social media campaigns, supporting their expansion into mid-funnel marketing channels.
To get started building a similar solution, consider the following next steps:
- Explore Amazon Bedrock for building generative AI applications
- Learn about Amazon SageMaker AI for hosting custom models
- Contact the AWS Generative AI Innovation Center to discuss your content generation challenges
Acknowledgement
Special thanks to Giuseppe Mascellero and Nikolas Zavitsanos for their contribution.