Organizations commonly rely on A/B testing to optimize user experience, messaging, and conversion flows. However, traditional A/B testing assigns users randomly and requires weeks of traffic to reach statistical significance. While effective, this process can be slow and might not fully leverage early signals in user behavior.
This post shows you how to build an AI-powered A/B testing engine using Amazon Bedrock, Amazon Elastic Container Service, Amazon DynamoDB, and the Model Context Protocol (MCP). The system improves traditional A/B testing by analyzing user context to make smarter variant assignment decisions during the experiment. This helps you reduce noise, identify behavioral patterns earlier, and reach a confident winner faster.
By the end of this post, you will have an architecture and reference implementation that delivers scalable, adaptive, and personalized experimentation using serverless AWS services.
The challenge with traditional A/B testing
Traditional A/B testing follows a familiar pattern: randomly assign users to variants, collect data, and select the winner.
This approach has limitations:
- Random assignment only – Even when early signals indicate meaningful differences
- Slow convergence – You will wait weeks to collect enough data
- High noise – The system might assign some users to variants that clearly mismatch their needs
- Manual Optimization – You will often need to segment data after the fact
A real scenario: why random assignment slows you down
Consider a retailer testing two Call-to-Action (CTA) buttons on its product pages:
- Variant A: “Buy Now”
- Variant B: “Buy Now – Free Shipping”
The first few days show Variant B performing well, so you might consider rolling it out. However, deeper session analysis reveals something interesting:
- Premium loyalty members, who already enjoy free shipping, hesitate when they see the “Free Shipping” message. Some even navigate to their account page to verify their benefits.
- Deal-oriented visitors arriving from coupon and discount websites engage far more with Variant B.
- Mobile users prefer Variant A because the shorter CTA fits better on smaller screens.
While Variant B seems to win early, different user behavior clusters influence this performance, not necessarily universal preference.
Assignment is random, therefore the experiment needs a long window to average out these effects—and you have to manually analyze multiple segments to make sense of it. This is where AI-assisted assignment can help improve the experiment.
Solution overview: AI-assisted variant assignment
The AI-assisted A/B testing engine upgrades classic experimentation by using real-time user context and early behavioral patterns to make smarter variant assignments.
The solution introduces an adaptive A/B testing engine built with Amazon Bedrock. Instead of committing every user to the same variant, the engine evaluates user context in real time, retrieves past behavioral data, and selects an optimal variant for that individual.
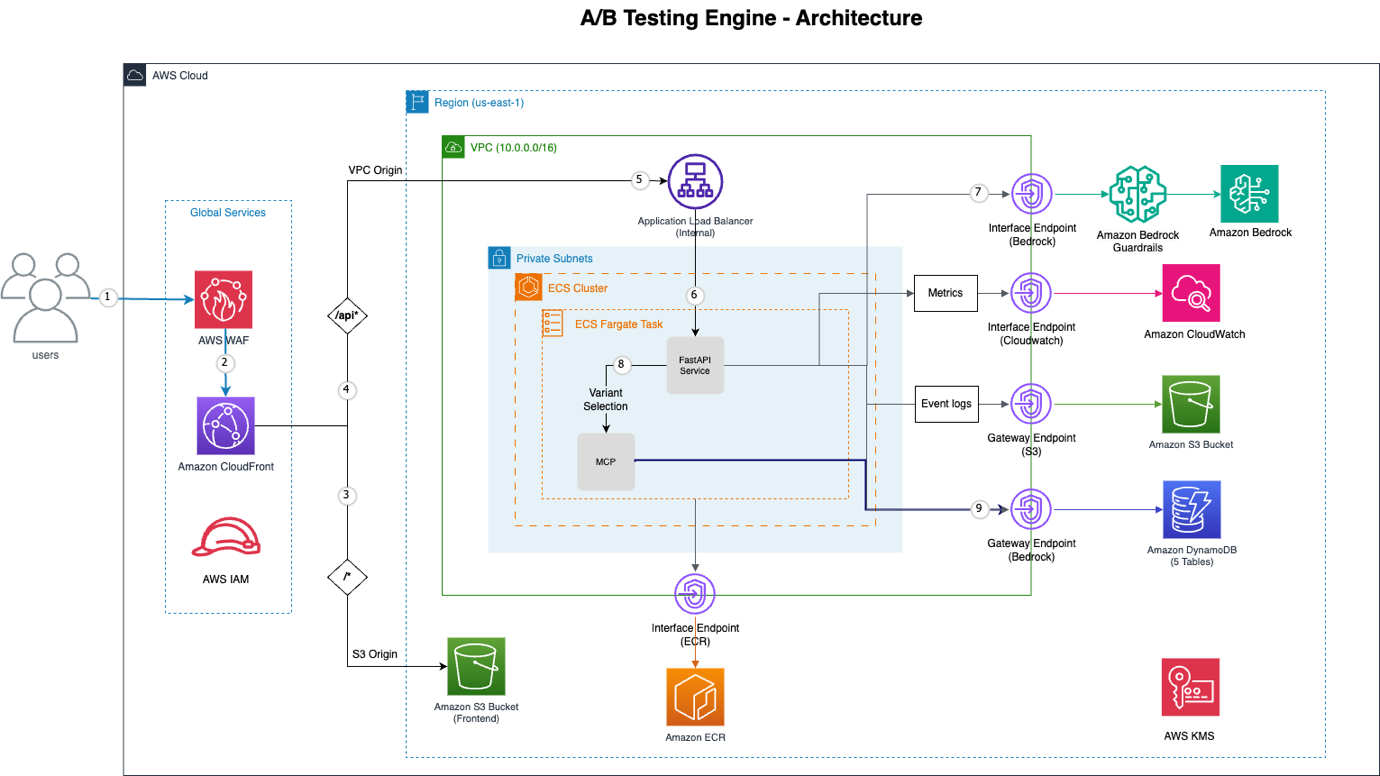
Figure 1: A/B Testing Engine Architecture
The architecture includes the following AWS components:
- Amazon CloudFront + AWS WAF – Global Content Delivery Network (CDN) with distributed denial-of-service (DDoS) protection, SQL injection deterrence, and rate limiting
- VPC Origin – Private connection from Amazon CloudFront to internal Application Load Balancer (no public internet exposure)
- Amazon ECS with AWS Fargate: Serverless container orchestration running FastAPI application
- Amazon Bedrock – AI decision engine using Claude Sonnet with native tool use
- Model Context Protocol (MCP) – Provides structured access to behavior and experiment data
- VPC Endpoints – Private connectivity to Amazon Bedrock, Amazon DynamoDB, Amazon S3, Amazon Elastic Container Registry (Amazon ECR), and Amazon CloudWatch
- Amazon DynamoDB – Five tables for experiments, events, assignments, profiles, and batch jobs
- Amazon Simple Storage Service (Amazon S3) – Static frontend hosting and event log storage
How Amazon Bedrock improves variant decisions
The core innovation lies in combining user context, behavioral history, similar-user patterns, and real-time performance data to select the optimal variant. This section reveals how the AI decision process works.
The AI decision prompt: what Amazon Bedrock sees
When a user triggers a variant request, the system constructs a comprehensive prompt that gives Amazon Bedrock the complete content needed to make an informed decision. Here’s what the actual prompt structure looks like:
Key elements of the prompt structure:
The two-tier prompt structure combines a system prompt and a user prompt.
The system prompt defines Amazon Bedrock as an “expert A/B testing optimization specialist” with access to 11 MCP tools (assignment checking, profile analysis, collaborative filtering, performance metrics, session analysis) and critical rules (check existing assignments first, 30% threshold for changes, JSON-only responses).
The user prompt provides complete decision context including user attributes (device, page, referrer, previous variants), personalization data (engagement score, conversion likelihood, interaction style), dynamically formatted variant configurations, real-time performance metrics, and a 5-step decision framework.
Together, both prompts help Amazon Bedrock to intelligently orchestrate tool calls and make data-driven variant selections with full transparency.
Why Amazon Bedrock over traditional ML
Traditional machine learning (ML) models (for example, decision trees, logistic regression, neural networks) have driven user segmentation for years. So why use Amazon Bedrock for variant assignment? The answer lies in four key capabilities:
Intelligent tool orchestration
Traditional ML requires hard-coded feature engineering. You must decide upfront which data to fetch and how to combine it. Amazon Bedrock, through the Model Context Protocol, intelligently decides which tools to call based on the situation.
Amazon Bedrock adapts its data gathering to each user’s unique situation. A new user triggers similarity analysis, while a returning user triggers profile analysis. An edge case might trigger all tools. You don’t program this logic—Amazon Bedrock reasons through it.
Multi-factor reasoning synthesis
Traditional ML models produce predictions without explanation. Amazon Bedrock provides reasoning that synthesizes multiple factors.
{
"variant_id": "B",
"confidence": 0.86,
"reasoning": "User's mobile device (small screen) strongly favors Variant B's shorter CTA. Similar mobile users show 23% higher conversion with B. User's high engagement score (0.83) suggests receptiveness to incentive messaging. Device constraints and behavioral alignment create strong signal for Variant B despite A's historical lead on desktop."
}This reasoning combines:
- Device constraints (technical factor)
- Similar user patterns (collaborative filtering)
- Personal engagement metrics (behavioral factor)
- Historical performance (statistical factor)
A traditional ML model might predict “Variant B: 78% probability” but can’t explain how device constraints interact with similar user patterns to inform that prediction.
Handling edge cases and conflicting signals
When signals conflict, Amazon Bedrock reasons through the trade-offs:
Zero training, instant adaption
Traditional ML requires:
- Historical training data collection (weeks/months)
- Feature engineering and model training
- Periodic retraining as patterns shift
- A/B testing the ML model itself
Amazon Bedrock works immediately:
- Day 1: Uses similar user patterns from existing data
- Day 2: Learns from yesterday’s outcomes
- Day 30: Sophisticated personalization based on accumulated insights
- You don’t need a retraining pipeline
Implementation deep dive
The following sections describe how the AI-assisted engine works behind the scenes.
Hybrid assignment strategy
New users → Hash-based (cost efficient)
Returning users → AI-driven (high value)
New users: Hash-based assignment (fast, no AI cost)
if is_new_user:
user_hash = int(hashlib.sha256(user_id.encode()).hexdigest(), 16)
return variants[index]This hybrid approach is crucial. New users have no behavioral data, so AI analysis provides minimal value. Hash-based assignment gives them a consistent experience while we collect data. After we have behavioral signals, AI selection delivers a significant lift.
MCP tool framework and execution
The Model Context Protocol (MCP) provides Amazon Bedrock with structured access to your behavioral data through an intelligent tool orchestration system. Instead of dumping all the data into the prompt (expensive and slow), Amazon Bedrock selectively calls tools to gather exactly the information needed. This creates a multi-turn conversation where it requests data, analyzes it, and makes decisions.
How tool execution works
Each Amazon Bedrock response might include a tool call. The FastAPI backend executes the tool, returns the result, and continues the conversation:
if response.stopReason == "tool_use":
tool_name = tool_call["name"]
payload = tool_call["input"]
result = await mcp.execute(tool_name, payload)
messages.append(
{
"role": "user",
"content": [{"toolResult": result}]
}
)This loop continues until the model produces the final decision JSON. This multi-turn conversation allows Amazon Bedrock to gather exactly the context it needs, analyze it and make a decision.
Key MCP tools
Tool 1: get_similar_users() – Collaborative Filtering
Finds users with similar behavioral patterns using cluster-based matching:
Tool 2: get_user_profile() – Behavioral Fingerprint
Retrieves comprehensive behavioral profile from DynamoDB PersonalizationProfile table:
Tool 3: get_variant_performance() – Real-Time Metrics
Retrieves performance data from Experiment table’s VariantPerformance nested object:
Storing AI insights back to profiles
After each variant selection, the system records the outcome to improve future decisions:
profile.update(
{
"last_selected_variant": decision.variant_id,
"confidence_score": decision.confidence,
"behavior_tags": extracted_signals
}
)
dynamodb.put_item(
TableName="user_profile",
Item=profile.to_item()
)Over time, as the system records more outcomes, user profiles become more accurate representations of individual preferences, enabling Amazon Bedrock to make better-informed variant selections.
Understanding confidence scores
Every AI decision includes a confident scores (0.0-1.0) that Amazon Bedrock generates as part of its reasoning process. This score reflects the system’s assessment of how certain it is about the variant selection based on the available data.
How Amazon Bedrock determines confidence:
Amazon Bedrock evaluates multiple factors when assigning confidence:-
- Data availability – More behavioral data and historical performance → higher confidence
- Signal consistency Aligned signals across user profile, similar users, and performance data → higher confidence
- Similar user evidence – Larger cluster of similar users with consistent preferences → higher confidence
- Statistical significance – Performance data that meets significance thresholds → higher confidence
- Profile maturity – Established user profiles with extensive history → higher confidence
The confidence score is a holistic assessment rather than a calculated metric, allowing it to weigh factors flexibly based on context.
Interpreting confidence scores:-
- 0.9–1.0: Extremely reliable – Strong evidence across all factors
- 0.7–0.89: High confidence – Good data quality with aligned signals
- 0.5–0.69: Moderate – Reasonable data but some uncertainty
- 0.3–0.49: Low – Limited data or conflicting signals
- < 0.3: Very low – Insufficient data for confident prediction
Context enrichment middleware
The middleware automatically enhances every request with device and session context:
user_agent = request.headers["user-agent"]
device = detect_device(user_agent)
referrer = classify_referrer(request.headers.get("referrer", ""))
user_context.device_type = device.type
user_context.referrer_type = referrerThis helps verify that Amazon Bedrock has rich context without requiring the frontend to send it explicitly.
A real example based on the retail scenario
Let’s revisit the retailer’s CTA test—this time showing the complete decision process of Amazon Bedrock, including actual tool calls.
User 1: loyalty member on mobile
Initial context
- Device: iPhone
- Loyalty: Premium loyalty member
- Browsing pattern: Fast, goal-oriented
- Referrer: Direct navigation
- Previous purchases: Frequent
Decision process
Tool Call 1:
get_user_assignment(user_id="user_001", experiment_id="cta_test_2024")
Response: No existing assignment exists
Tool Call 2:
get_user_profile(user_id="user_001")
Response:
{
"engagement_score": 0.89,
"conversion_likelihood": 0.24,
"interaction_style": "focused",
"attention_span": "short",
"successful_variants": ["A", "simple_design"],
"confidence_score": 0.87
}
Tool Call 3:
get_similar_users(user_id="user_001", limit=5)
Response:
{
"count": 52,
"avg_conversion_rate": 0.21,
"preferred_variants": ["A"],
"shared_characteristics": ["mobile", "loyalty_member", "focused_buyer"]
}
Tool Call 4:
get_variant_performance(experiment_id="cta_test_2024", variant_id="A")
Response:
{
"current_performance":
{
"impressions": 3900,
"clicks": 312,
"conversions": 125,
"conversion_rate": 0.032,
"confidence": 0.89
},
"has_performance_data": true
}Amazon Bedrock evaluates the data and returns:
User 2: first-time visitor arriving from a coupon siteInitial context
- Device: Android
- No loyalty status
- Browsing pattern: Slow, comparison-focused
- Referrer: Deal-aggregation website
Decision process
Amazon Bedrock selects:
Key differences
User 1 (Established Profile)
- Relied heavily on personal behavioral history (0.87 confidence)
- Similar users confirmed but didn’t drive decision
- Device + loyalty status are considered as key factors
User 2 (New User)
- Minimal personal data (0.12 confidence)
- Heavily relied on similar user patterns (39 similar users)
- Referrer context was decisive signal
- Still achieved 0.91 decision confidence through strong contextual signals
This demonstrates how the system adapts its data gathering strategy based on available information-using personal history when available, and similar user patterns when not.
Future enhancements
This system provides a foundation for advanced personalization:
- Dynamic Variant Generation – Instead of selecting from predefined variants, use Amazon Bedrock to generate custom content for each user. Imagine CTAs that adapt their messaging, color, and urgency based on individual behavior.
- Multi-armed Bandits – Combine AI personalization with bandit algorithms for automatic traffic allocation. Shift traffic to winning variants while still exploring new options.
- Cross-experiment Learning – Share insights across experiments. If a user responds well to urgency messaging in one test, apply that knowledge to other tests automatically.
- Real-time Optimization – Use streaming data from Amazon Kinesis to update profiles in real-time. React to user behavior within seconds, not minutes.
- Advanced Segmentation – Let AI discover user segments automatically through clustering. No more manual segment creation—the system finds patterns that you didn’t know existed.
Conclusion
In this post, you learned how to build an adaptive A/B testing engine using Amazon Bedrock and the Model Context Protocol. This solution transitions experimentation from static, random assignment to an intelligent, continuously learning personalization engine. Key benefits include:
- Personalized variant decisions
- Nearly continuous learning from user behavior
- Serverless architecture with minimal operational overhead
- Predictable costs through hybrid assignment
- Deep integration with AWS services
To get started, deploy the reference architecture and gradually enable AI-powered decisions as user data matures.
To implement this solution in your environment:
- Start with the basics – Deploy the infrastructure using the provided AWS CloudFormation templates. Begin with a hash-based assignment for all users to establish a baseline.
- Add personalization gradually – Enable AI-powered selection for returning users after you have behavioral data. Start with a small percentage of traffic and monitor the results.
- Expand MCP tools – Add custom tools to the MCP server based on your specific business needs. Consider tools for inventory data, pricing information, or customer service history.
- Monitor and optimize – Use Amazon CloudWatch dashboards to track variant assignment latency, Amazon Bedrock API costs, and conversion metrics. Set up alarms for anomalies.
- Explore advanced features – Implement dynamic variant generation, multi-armed bandits, or cross-experiment learning as your system matures.
You can find the complete code for this solution, including FastAPI backend, React frontend, CloudFormation templates, and MCP server implementation, in the GitHub – A/B Testing Engine.
To avoid incurring ongoing charges, delete the resources that you created during this walkthrough. For detailed cleanup instructions including step-by-step commands and verification steps, see the Infrastructure Cleanup Guide.