A special thanks goes to the Verizon Connect team who’s been working very hard on the project: Matteo Simoncini, Luca Bravi, Alberto Rossettini, Martin Villarruel, Ceyhun Unlu, Adriel Zuquini, Andrea Benericetti.
Fleet managers today face an overwhelming challenge: transforming data overload into actionable insights. When you’re managing thousands of vehicles, each generating hundreds of daily data points, identifying critical patterns becomes nearly impossible through manual analysis. Verizon Connect, a global fleet management solutions provider serving businesses worldwide through its Reveal platform, encountered this exact challenge at scale.
With over 1.2 million active vehicle subscriptions generating over 500 million data points daily across 80,000 unique data indicators, fleet managers were drowning in this data and forced to hunt for anomalies across fragmented paper logs and reactive spreadsheets. The sheer volume made it impossible to identify emerging safety issues, maintenance needs, or operational inefficiencies before they became costly problems.Rather than building another static dashboard or rule-based automation system, which only catches predefined patterns, Verizon Connect chose agentic AI to replace that manual guesswork with a centralized intelligence solution. Agentic AI dynamically investigates new patterns, asks follow-up questions, and adapts its analysis based on what it discovers, making it well suited for the unpredictable nature of fleet operations.
In this post, we show you how Verizon Connect built and scaled an agentic AI solution to transform overwhelming fleet data into clear, actionable insights for 100,000 users daily. We walk you through the architectural decisions, implementation challenges, and measurable results that can guide your own data-to-insights transformation.
Building scalable architecture
The solution handles data at scale while maintaining cost-efficiency. The following figure describes the core components. Later in this section, we walk through and discuss the various components of the solution and tie them together in the ‘Overall architecture’ section.
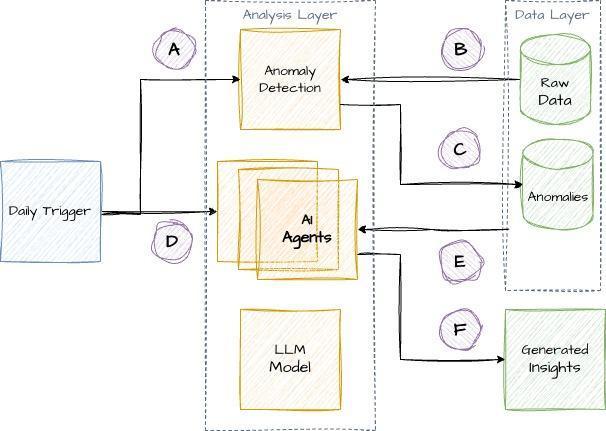
Figure 1 – High-level solution architecture
The high-level description of the components and the logical flow is as follows.
- Orchestration begins – The daily trigger initiates the workflow by activating the anomaly detection module within the analysis layer.
- Data ingestion – The module pulls structured information from the raw data store. This is where the computationally heavy lifting happens.
- Targeted outputs – Rather than asking a large language model (LLM) to “find needles in a haystack,” this module identifies specific anomalies and writes them to a dedicated anomalies table. By offloading numerical analysis to specialized code, we avoid the scale and accuracy issues LLMs face with raw tabular data.
- AI agent activation – After the anomalies are ready, the manager triggers the AI agents. To improve performance, multiple agents can run in parallel, each focusing on a different customer or data segment.
- Reasoning & context – The AI agent orchestrates the final analysis. It queries the anomalies for the what and refers back to the raw data for the why, using the LLM to synthesize these inputs into a coherent narrative.
- Insight delivery – The final reasoning is stored as generated insights, which are then served to the end-user via the Reveal application.
Components of the solution
Anomaly detection
A common pitfall in AI engineering is asking an LLM to perform numerical analysis on large-scale raw tabular data. As AWS Prescriptive Guidance notes, LLMs can struggle with complex table structures and numerical extraction at scale. To address this, we built a serverless statistical model using AWS Step Functions and AWS Lambda (See Figure 4). This model performs the computationally intensive work of anomaly detection on structured data. It identifies what the anomaly is, so the AI agent can focus on why it occurred and how to address it.
AI agent
We selected Strands Agents, an open source SDK for building and executing AI agents, running in a serverless AWS Lambda environment. This deployment pattern scales horizontally based on your demand. The AI agent operates through a dynamic reasoning loop, autonomously determining the necessary investigation path rather than following a fixed set of steps. From the following description you can notice that the AI agent is stateless, the context required for the insights generation is retrieved fresh at analysis time.
The AI agent uses specific tools to:
- Retrieve pre-calculated anomalies from Amazon Simple Storage Service (Amazon S3).
- Query additional context from Amazon Aurora for raw data and Amazon DynamoDB for historical insights.
- Write final insights back to Amazon S3.
- Track task request status in Amazon DynamoDB.
Two-stage agentic architecture
The insight generation follows a two-stage approach, each using the LLM’s reasoning capabilities differently:
Stage 1: Summary generation (anomaly aggregation & prioritization)In this first stage, the agent receives a set of raw anomalies detected across the fleet. Rather than processing each anomaly individually, the LLM autonomously decides how to aggregate them into coherent insight candidates. It can group anomalies by:
- Common root causes (such as multiple vehicles showing the same behavior pattern)
- Temporal correlation (events concentrated on specific dates)
- Categorical similarity (related safety or efficiency metrics)
Both the grouping logic and the selection criteria are entirely at the LLM’s discretion. The system doesn’t impose fixed rules on how anomalies should be combined. After aggregation, the agent assigns a relevance score to each candidate’s insight based on factors such as severity, recurrence, fleet-wide impact, and actionability. From these scored candidates, the agent selects the top four most relevant insights to proceed to detailed generation. With this approach prioritization adapts to the specific context of each user’s fleet, rather than relying on static business rules that might miss emerging patterns.
Stage 2: Detailed generation (agentic tool-based Investigation)The second stage is where the agentic nature of the system becomes critical. For each summary insight, a separate agent instance is spawned with access to data retrieval tools. The agent autonomously decides which tools to call, in what sequence, and how many times—iterating until it has gathered sufficient evidence to produce a data-backed insight. Now that the agent execution is explained, let’s examine why an agentic approach is essential for this use case. Fleet management involves countless variables and unpredictable scenarios that require dynamic investigation rather than predetermined logic, that creates two fundamental limitations:
- Finite pattern coverage: Code can only detect patterns that were explicitly programmed. Edge cases, novel correlations, or unexpected data distributions go unnoticed.
- Rigid investigation flows: A script follows predetermined steps regardless of what the data reveals mid-analysis.
In contrast, the AI agent can discover patterns of any nature, including edge cases that weren’t anticipated during development. If the data suggests an unexpected correlation (such as harsh braking events correlating with specific time-of-day patterns, or a vehicle’s behavior changing after a particular date), the agent can pivot its investigation strategy in real time, making additional tool calls to explore these emergent hypotheses. This flexibility is particularly valuable in fleet management, where:
- Driver behavior varies unpredictably
- External factors (weather, traffic, road conditions) create non-obvious correlations
- Fleet composition and usage patterns evolve over time
- New anomaly types might emerge that weren’t present in historical data
Example of flow orchestration
- Initial discovery: The agent identifies a summary insight reporting a 30 percent increase in harsh braking events across the entire fleet.
- Establishing a baseline: It autonomously decides to pull the fleet-wide historical average for the last 30 days to confirm if this spike is a true anomaly or just a typical seasonal trend.
- Pattern recognition: Upon seeing that the spike is concentrated on specific dates, the agent shifts its focus to a daily breakdown. It discovers that most of these safety events occurred on the same two days.
- Targeted drill-down: Based on those dates, the agent identifies that vehicles 1015, 1142, and 1032 were responsible for nearly 70 percent of the events.
- Comparative analysis: It then makes a final, targeted request to compare the historical performance of Vehicle 1015 against its current behavior to see if the driver’s profile has fundamentally changed.
- Synthesis: only after “connecting these dots” does the agent terminate the loop and generate a final, data-backed insight that highlights the specific drivers and dates involved.
Large language model
To optimize price-performance, we first used the high-tier Claude 4.5 Sonnet to validate logic and insight quality. Post-validation, we transitioned to the more cost-efficient Claude 4.5 Haiku for our production use case. Further price-performance optimization led us to Amazon Nova 2 Lite, a lightning-fast multimodal model, which delivers comparable insight quality while reducing input token costs by 70 percent compared to Claude 4.5 Haiku. This substantial saving is critical since the workload is dominated by input tokens (telematics data, anomalies, context). The efficiency of Nova 2 Lite enables Verizon Connect to deliver AI insights more cost-effectively to its entire user base. Quality was maintained via an automated testing suite and a gold-standard dataset, ensuring a battle-tested solution upon full release. LLMs are hosted at scale in Amazon Bedrock, a fully managed service with comprehensive generative AI capability, security, privacy and responsible AI features.
Daily trigger management and concurrency
To provide insights ready at the start of their business day to the 100,000 users, we use Amazon Simple Queue Service (Amazon SQS) to manage execution. By controlling the maximum concurrency of the SQS-to-Lambda trigger, we can:
- Smooth out spikes in API demand
- Stay within Amazon Bedrock quotas: Tokens Per Minute (TPM) and Requests Per Minute (RPM)
- Provide reliable delivery without over-provisioning resources
To illustrate, consider a scenario delivering insights for customers across the entire United States. The target delivery of insights is 8:00 AM ET, based on data generated up to Midnight PT the previous day. Given the three-hour time zone difference, the end-to-end process must be completed within a five-hour window. Allocating one hour for anomaly detection leaves a four-hour window for the AI Agent and LLM to generate insights. At a rate of 1,500 RPM (adjustable), the insight generation phase will take approximately 1.25 hours, well within our operational requirements.
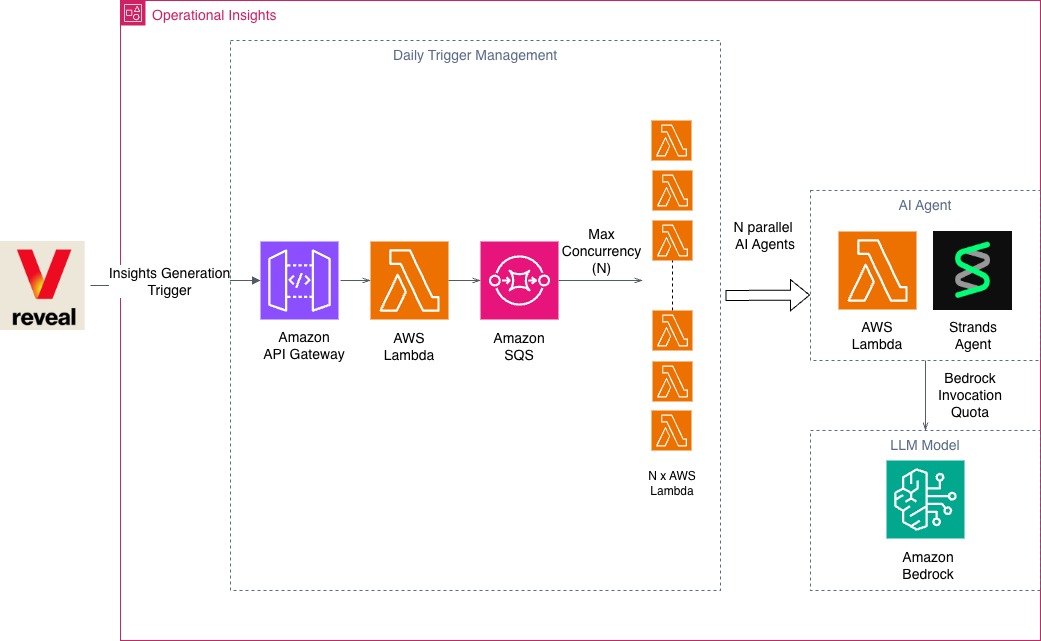
Figure 2 – Maximum Concurrency SQS-to-Lambda details
Generated insights
The insights the agent generates are ready for the Reveal application to consume. Upon login, new insights appear in a dedicated panel on the live map, Reveal’s most visited page, so that every user sees relevant insights immediately. Each insight is clickable, leading to a detailed page with the full analysis.
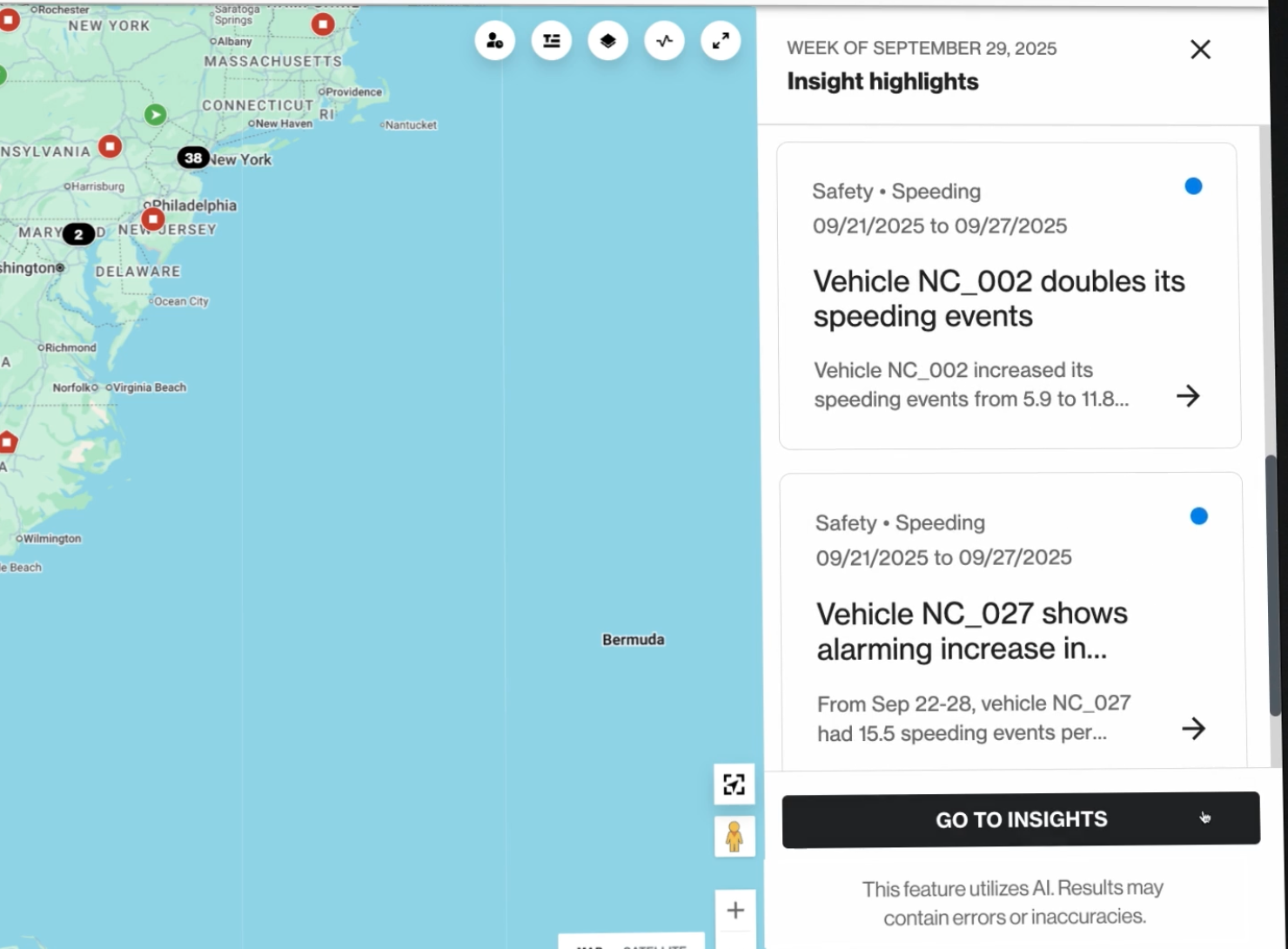
Figure 3 – Reveal’s most visited page includes links to Operational Insights results.
Overall architecture
The overall architecture puts together these four components: Anomaly detection, parallelization of requests, insights generation engine, and storage of generated insights for consumption by Reveal application.
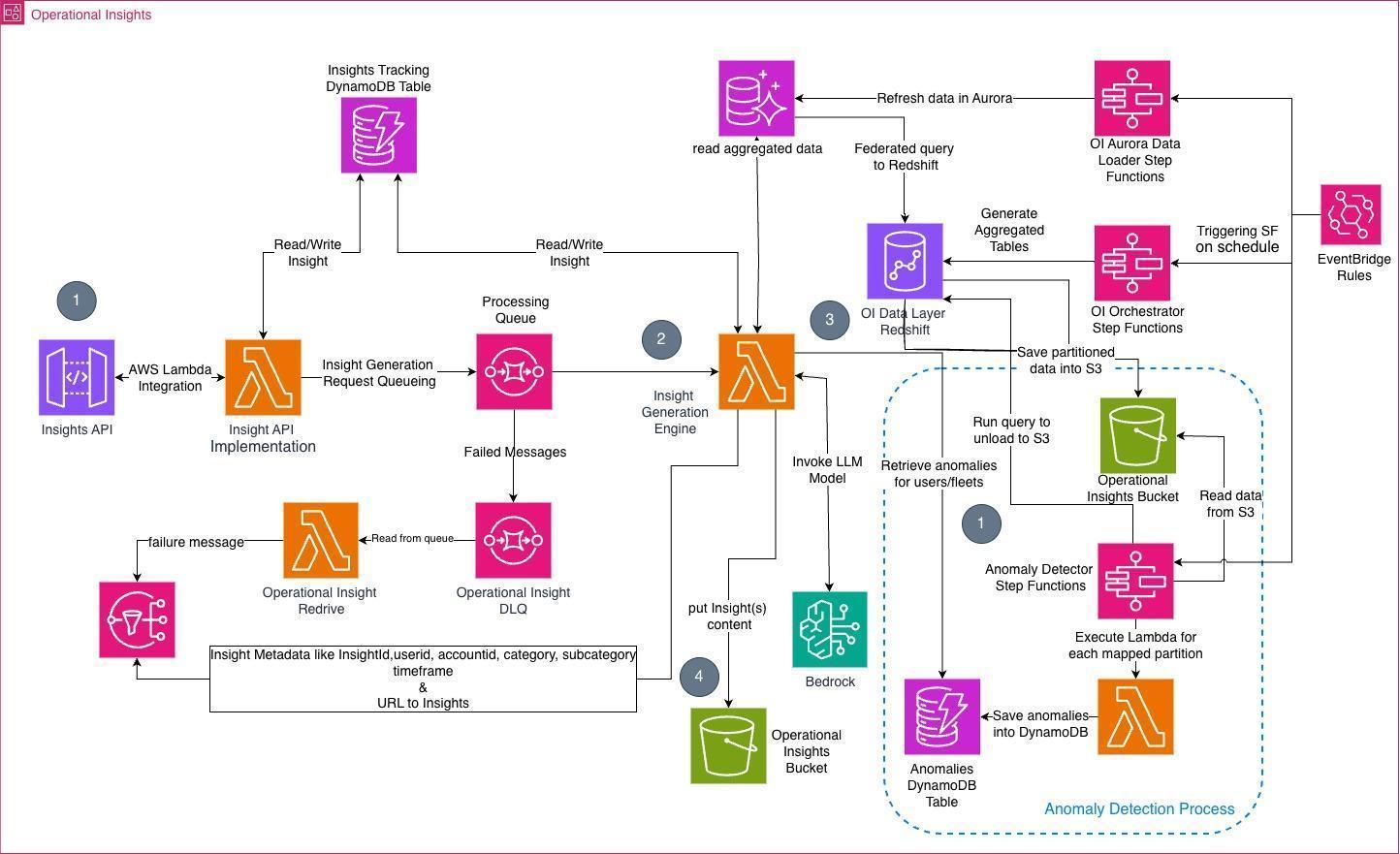
Figure 4 – Overall architecture
To understand how these components work together, consider the following workflow: An insights request is triggered, including the list of customer IDs for which insights must be calculated. The statistical model performs anomaly detection and stores results in Amazon S3.
- N parallel requests are triggered as described earlier.
- N agents analyze data, create insights, and save them to Amazon S3. In this phase, agents invoke Amazon Bedrock APIs to reach the selected model.
- The Reveal application can access the insights stored in Amazon S3.
The result: actionable intelligence
The Operational Insights feature was rolled out to Verizon Connects users in November 2025,and has served fleet managers with clear, natural language narratives like the following:
- Safety pattern detection: “Your fleet saw a 100% increase in harsh braking this week. Interestingly, this coincides with a reduction in harsh acceleration, suggesting driver fatigue or increased congestion.”
- Operational efficiency: “Vehicle #90000 is idling for 50% of its engine-on time, significantly above your fleet average. This represents unnecessary fuel cost.”
- Fleet performance: “Daily mileage is down 59%, but speeding events are up 54%. This suggests vehicles are traveling shorter distances at higher speeds—consider route optimization.”
Conclusion and looking ahead
In this post, we showed how Verizon Connect built a scalable Agentic AI solution on AWS that transforms raw IoT telematics data into actionable fleet insights for over 100,000 users. The architecture combines Amazon Bedrock, Strands Agents, AWS Step Functions, Amazon SQS, and a multi-tier data layer to deliver reliable, cost-efficient insights at scale.
As the AI landscape evolves, we plan to migrate from AWS Lambda based agent deployment to Amazon Bedrock AgentCore Runtime to further streamline our AWS Lambda execution and use Model Context Protocol (MCP) for faster tool integration.
To implement an agentic AI solution effectively, begin with a small-scale pilot to validate a basic use case and establish cost-efficiency. After the initial value is proven, expand the system by integrating automated workflows and data-driven personalization. The final stage involves transitioning to a full enterprise deployment that supports advanced orchestration and real-time processing across the entire organization.Start building today:
- Start with the foundations: Amazon Bedrock for managed AI services and AWS Lambda for serverless agent hosting
- Add orchestration: AWS Step Functions for workflow management and Amazon SQS for scalable queueing
- Store and retrieve data: Amazon S3 for object storage, Amazon Aurora for structured data, and Amazon DynamoDB for fast lookups
- Explore agent frameworks: Strands Agents documentation for open source agent development