This post was written with Lokesha Thimmegowda, Muppirala Venkata Krishna Kumar, and Maraka Vishwadev of CBRE.
CBRE is the world’s largest commercial real estate services and investment firm. The company serves clients in more than 100 countries and offers services ranging from capital markets and leasing advisory to investment management, project management and facilities management.
CBRE uses AI to improve commercial real estate solutions with advanced analytics, automated workflows, and predictive insights. The chance to unlock value with AI in the commercial real estate lifecycle begins with data at scale. With the industry’s largest dataset and a comprehensive suite of enterprise-grade technology, the company has implemented a range of AI solutions to boost individual productivity and support broad-scale transformation.
This blog post describes how CBRE and AWS partnered to transform how property management professionals access information, creating a next-generation search and digital assistant experience that unifies access across many types of property data using Amazon Bedrock, Amazon OpenSearch Service, Amazon Relational Database Service, Amazon Elastic Container Service, and AWS Lambda.
Unified property management search challenges
CBRE’s proprietary PULSE system consolidates a wide range of essential property data—covering structured data from relational databases that record transactions and unstructured data stored in document repositories containing everything from lease agreements to property inspections. In the past, property management professionals had to sift through millions of documents and switch between multiple different systems to locate property maintenance details. Data was scattered across 10 distinct sources and four separate databases, which made it hard to get complete answers. This fragmented setup reduced productivity and made it difficult to uncover key insights about property operations.
Experts in property management, not database syntax, needed to ask complex questions in natural language, quickly synthesize disparate information, and avoid manual review of lengthy documents.
The challenge: deliver an intuitive, unified search solution bridging structured and unstructured content, with robust security, enterprise-grade performance and reliability.
Solution architecture
CBRE implemented a global search solution within PULSE, powered by Amazon Bedrock, to address these challenges. The search architecture is designed for a seamless, intelligent, and secure information retrieval experience across diverse data types. It orchestrates an interplay of user interaction, AI-driven processing, and robust data storage.
CBRE’s PULSE search solution uses Amazon Bedrock for the rapid deployment of generative AI capabilities by using multiple foundation models through a single API. CBRE’s implementation uses Amazon Nova Pro for SQL query generation, achieving a 67% reduction in processing time, while Claude Haiku powers intelligent document interactions. The solution maintains enterprise-grade security for all property data. By combining Amazon Bedrock capabilities with Retrieval Augmented Generation (RAG) and Amazon OpenSearch Service, CBRE created a unified search experience across more than eight million documents and multiple databases, fundamentally transforming how property professionals access and analyze business-critical information.
The following diagram illustrates the architecture for the solution that CBRE implemented in AWS:
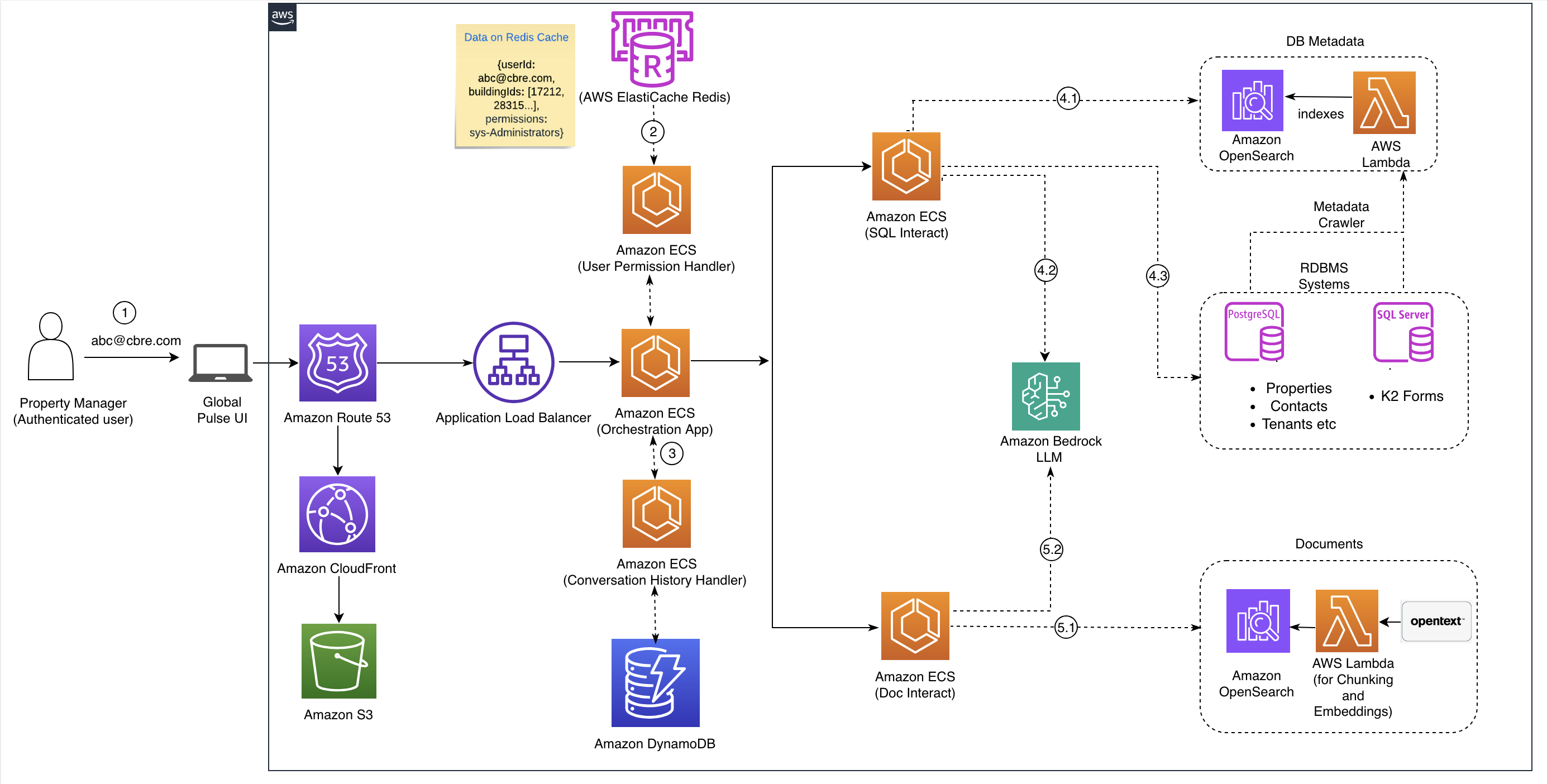
Let us go through the flow for the solution:
- Property Manager and PULSE UI: Property managers interact through the intuitive PULSE user interface, which serves as the gateway for both traditional keyword searches and natural language queries (NLQ). The UI displays search results, supports document conversations, and presents intelligent summaries in desktop and mobile.
- Dynamic search execution: When users submit requests, the system first retrieves user-specific permissions from Amazon ElastiCache for Redis, chosen for its low latency and high throughput. Search operations across Amazon OpenSearch and transactional databases are then constrained by these user-specific permissions, making sure users only access authorized results with real-time granular control.
- Orchestration layer: This central control hub serves as the application’s brain, receiving user requests from PULSE UI and intelligently routing them to appropriate backend services. Key responsibilities include:
- Routing queries to relevant data systems (structured databases, unstructured documents, or both for deep search).
- Initiating parallel searches across SQL Interact and Doc Interact components.
- Merging, de-duplicating, and ranking results from disparate sources for unified outcomes.
- Managing conversation history through Amazon DynamoDB integration.
- SQL interact component (structured data search): This pathway manages interactions with structured relational databases (RDBMS) through these key steps:
- 4.1 Database metadata retrieval: Dynamically fetches schema details (for example, table names, column names, data types, relationships, constraints) for entities like property, contacts, and tenants from an Amazon OpenSearch index.
- 4.2 Amazon Bedrock LLM (Amazon Nova Pro): Interprets the user’s natural language query alongside schema metadata, translating it into accurate, optimized SQL queries tailored to the database. The solution reduced SQL query generation time from an average of 12 seconds earlier to 4 seconds using Amazon Nova Pro.
- 4.3 RDBMS systems (PostgreSQL, MS SQL): Actual transactional databases, such as PostgreSQL and MS SQL, which house the core structured property management data (for example, properties, contacts, tenants, K2 forms). They execute the LLM-generated SQL queries and return the structured tabular results back to the SQL Interact component.
- DocInteract Component (Unstructured Document Search): This pathway is specifically designed for intelligent search and interaction with unstructured documents.
- 5.1 Vector Store (OpenSearch Cluster): Stores documents, including those from OpenText, as high-dimensional vectors for efficient semantic search using techniques like k-Nearest Neighbors while prioritizing speed and accuracy with metadata filtering.
- 5.2 Amazon Bedrock LLM (Claude Haiku): Interprets NLQs and translates them into optimized OpenSearch DSL queries, while powering the “Chat With AI” feature for direct document interaction, generating concise, conversational responses including answers, summaries, and natural dialogue.
Having established the core architecture with both SQL Interact and DocInteract components, the following sections explore the specific optimizations and innovations implemented for each data type, beginning with structured data search enhancements.
Structured data search
Building on the SQL interact component outlined in the architecture, the PULSE Search application offers two search methods for accessing structured data in PostgreSQL and MS SQL. Keyword Search scans the fields and schemas for specific terms, facilitating comprehensive coverage of the entire data system. With Natural Language Query (NLQ) Search users can interact with the databases using everyday language, translating queries into database queries. Both methods support property managers to efficiently locate and retrieve information across the database modules.
Database layer search performance enhancement at the SQL level
Our unique challenge involved implementing application-wide keyword searches that needed to scan across the columns in database tables – a non-conventional requirement compared to traditional indexed column-specific searches in RDBMS systems. This universal search capability was essential for user experience, allowing information discovery without knowing specific column names or data structures.
We leveraged native full-text search capabilities in both PostgreSQL and MS SQL Server databases:
- PostgreSQL Implementation:
- Microsoft SQL Server Implementation:
Note: Our implementation uses specialized text search columns (textsearchable_all_col) concatenating the searchable fields from the view pd_db_view_name, while ms_db_view_name represents a view created with full-text search indexing.
This optimization delivered an 80% improvement in query performance by harnessing native database capabilities while balancing comprehensive search coverage with optimal database performance through specialized indexing algorithms.
Database layer search performance enhancement at the SQL interact API level
We implemented several optimizations in database search functionality targeting three key performances (KPIs): Accuracy (precision of results), Consistency (reproducible outcomes), and Relevancy (making sure results align with user intent). The enhancements reduced response latency while simultaneously boosting these ACR metrics, resulting in faster and more dependable search results.
Prompt Engineering Changes: We implemented a comprehensive approach to prompt management and optimization, focusing on the following factors.
- Configurability: We implemented modular prompt templates stored in external files to enable version control, simplified management, and reduced prompt size, improving performance and maintainability.
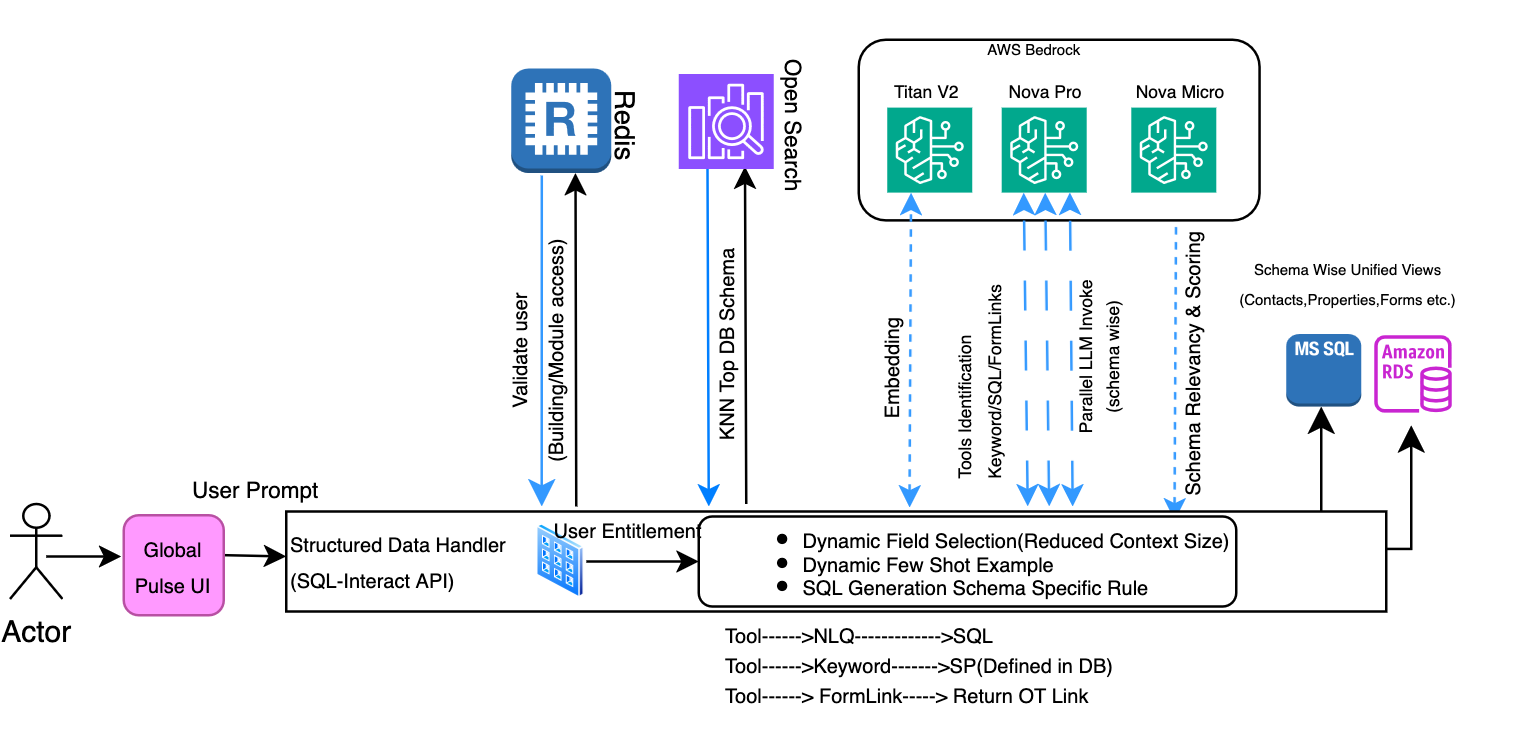
- Dynamic field selection for context window reduction: The system uses KNN-based similarity search to filter and select only the most relevant schema fields aligned with user intent, reducing context window size and optimizing prompt effectiveness.
- Dynamic few-shot example: The system intelligently selects the most relevant few-shot example from a configuration file using KNN-based similarity search for the SQL generation. This smart, context-aware approach makes sure that only the most pertinent example is included in the prompt, minimizing unnecessary data overhead. This approach helped in getting consistent and accurate SQL generation from LLM.
- Business rule integration: The system maintains a centralized repository of business rules in a dedicated schema wise configuration file, making rule management and updates streamlined and efficient. During prompt generation, relevant business rules are dynamically integrated into prompts, facilitating consistency in rule application while providing flexibility for updates and maintenance.
- LLM score-based relevancy: We added a fourth LLM call to evaluate and reorder schema relevance after initial KNN retrieval, addressing challenges where vector search returned irrelevant or poorly ordered schemas.For example, when processing a user query about property or contact information, the vector search might return three schemas, but:
- The third schema might be irrelevant to the query.
- The ordering of the two relevant schemas might not reflect their true relevancy to the query.
To address these challenges, we introduced an additional LLM processing (4th LLM parallel call) step that:
- Evaluates the relevance of each schema to the user query.
- Assigns relevancy scores to determine schema importance.
- Reorders schemas based on their actual relevance to the query.
This enhancement improved our schema selection process by:
- Making sure only truly relevant schemas are selected.
- Maintaining proper relevancy ordering.
- Providing more accurate context for subsequent query processing.
These enhancements improved schema selection by verifying only truly relevant schemas are processed, maintaining proper relevancy ordering, and providing more accurate context for query processing. The result was more precise, contextually appropriate responses and improved overall application performance.
Parallel LLM inference for SQL generation with Amazon Nova Pro
We implemented a comprehensive parallel processing architecture for NLQ to SQL conversion, enhancing system performance and efficiency. The solution introduces concurrent schema-based API calls to the LLM inference engine, with asynchronous processing for multiple schema evaluations. Our security-first approach authenticates and validates user entitlements while performing context-aware schema identification that incorporates similarity search and enforces access permissions. The system only processes schemas for which the user has explicit authorization, facilitating foundational data security. Following authentication, the system dynamically generates prompts (as detailed in our prompt engineering framework) and initiates concurrent processing of the most relevant schemas through parallel LLM inference calls. Before execution, it enhances the generated SQL queries with mandatory security joins that enforce building-level access controls, restricting users to their authorized buildings only.
Finalized SQL queries are executed on respective database systems (PostgreSQL or SQL Server). The system processes the query results and returns them as a structured API response, maintaining security and data integrity throughout the entire workflow. This architecture facilitates both optimal performance through parallel processing and comprehensive security through multi-layered access controls.
This integrated approach incorporates concurrent validation of generated SQL queries, resulting in reduced processing time and improved system throughput and reduced inference latency with Amazon Nova Pro. With introduction of Nova Pro there was significant improvement in inference latency. The framework’s architecture facilitates efficient resource utilization while maintaining high accuracy in SQL query generation, making it particularly effective for handling complex database operations and high-volume query processing requirements.
Enhancing unstructured data search
The PULSE document search uses two main methods, enhanced by purpose-built specialized search functions. Users can use the streamlined Keyword Search to precisely locate terms within documents and metadata for fast retrieval when precise search terms are known. This straightforward approach makes sure users can quickly locate exact matches across the entire document landscape. The second method, Natural Language Query (NLQ) Search, supports interaction with documents using everyday language, interpreting intent and converting queries into search parameters—particularly powerful for complex or concept -based queries. Complementing these core search methods, the system offers specialized search capabilities including Favorites and Collections search so users can efficiently navigate their personally curated document sets and shared collections. Additionally, the system provides intelligent document upload search functionality that helps users quickly locate appropriate document categories and upload locations based on document types and property contexts.
The search infrastructure supports comprehensive file formats including PDFs, Microsoft Office documents (Word, Excel, PowerPoint), emails (MSG), images (JPG, PNG), text files, HTML files, and various other document types, facilitating comprehensive coverage across the document categories in the property management environment.
Prompt engineering and management optimization
Our Document Search system incorporates advanced prompt engineering techniques to enhance search accuracy, efficiency, and maintainability. Let’s explore the key features of our prompt management system and the value they bring to the search experience.
Two-stage prompt architecture and modular prompt management:
At the core of our system is a two-stage prompt architecture. This design separates tool selection from task execution for more efficient and accurate query processing.
This architecture reduces token usage by up to 60% by loading only necessary prompts per query processing stage. The lightweight initial stage quickly routes queries to appropriate tools, while specialized prompts handle the actual execution with focused context, improving both performance and accuracy in tool selection and query execution.
Our modular prompt management system stores prompts in external configuration files for dynamic loading based on context and supporting personalization. It supports prompt updates without code deployments, cutting update cycles from hours to minutes. This architecture facilitates A/B testing of different prompt variations and quick rollbacks, enhancing system adaptability and reliability.
The system implements context-aware prompt selection, adapting to query types, document characteristics, and search contexts. This approach makes sure that the most appropriate prompt and query structure are used for each unique search scenario. For example, the system distinguishes between different question types (for example, ‘list_question’) for tailored processing of various query intents.
Search algorithm optimization
Our document search system implements search algorithms that combine vector-based semantic search with traditional text-based approaches to search across document metadata and content. We use different query strategies optimized for specific search scenarios.
Keyword search:
Keyword search uses a dual strategy combining both metadata and content searches using phrase matching. A fixed query template structure facilitates efficiency and consistency, incorporating predefined metadata, content, permission rules, and building ID constraints, while dynamically integrating user-specific terms and roles. This approach allows for fast and reliable searches while maintaining proper access controls and relevance.
User queries like “lease agreement” or “property tax 2023” are parsed into component words, each requiring a match in the document content for relevancy, facilitating precise results.
Similarly, for metadata searches, the system uses phrase searching across metadata fields:
This approach provides exact matching capabilities across document metadata, facilitating precise results when users are searching for specific document properties. The system executes both search types concurrently and results from both searches are then merged and deduplicated, with scoring normalized across both result sets.
Natural language query search:
Our NLQ search combines LLM-generated queries with vector-based semantic search through two main components. The metadata search uses an LLM to generate OpenSearch queries from natural language input. For instance, “Find lease agreements mentioning early termination for tech companies from last year” is transformed into a structured query that searches across document types, dates, property names and other metadata fields.
For content searches, we employ KNN vector search with a K-factor of 5 to identify semantically similar content. The system converts queries into vector embeddings and executes both metadata and content searches simultaneously, combining results while minimizing duplicates.
Chat with Document (digital assistant for in-depth document interaction):
The Chat with Document feature supports natural conversation with specific documents after initial search. Users can ask questions, request summaries, or seek specific information from selected documents through a straightforward interaction process.
When engaged, the system retrieves the complete document content using its node identifier and processes user queries through a streamlined pipeline. Each query is handled by an LLM using carefully constructed prompts that combine the user’s question with relevant document context.
With this capability users can extract information from complex documents efficiently. For example, property managers can quickly understand lease terms or payment schedules without manually scanning lengthy agreements. The feature provides instant summaries and explanations for rapid information access and decision-making in document-intensive workflows.
Scaling document ingestion
To handle high-throughput document processing and large-scale enterprise ingestion, our ingestion pipeline uses asynchronous Amazon Textract for scalable, parallel text extraction. The architecture efficiently processes diverse file types-PDFs, PPTs, Word documents, Excel files and images-even with hundreds of pages or high-resolution content. Once a document is uploaded to an Amazon S3 bucket, a message triggers an SQS queue, invoking a Lambda function that initiates an asynchronous Textract job, offloading heavy extraction and OCR tasks without blocking execution.
For text documents, the system reads the file from Amazon S3 and submits it to Amazon Textract’s asynchronous API, which processes the document in the background. Once the job completes, the results are retrieved and parsed to extract structured text. This text is then chunked intelligently—based on token count or semantic boundaries—and passed through a Bedrock embedding model (For example, Amazon Titan Text embeddings v2). Each chunk is enriched with metadata and indexed into Amazon OpenSearch for fast and context-aware search capabilities. Once ingested, our intelligent query strategy, driven by user and CBRE market lookups, dynamically directs searches to the relevant OpenSearch indexes.
Image files follow a similar flow but use Amazon Bedrock Claude 3 Haiku for OCR after base64 conversion. Extracted text is then chunked, embedded, and indexed like standard text documents.
Security and access control
User authentication and authorization occurs through a multi-layered security process:
- Access token validation: The system verifies the user’s identity by validating the user identity in Microsoft B2C and their access token against each request. The user is also checked for their authorization to access application.
- Entitlement verification: Simultaneously, the system checks the user’s permissions in a Redis database to verify they have the appropriate access rights to specific modules in application and database schemas (entitlements) they’re authorized to query on.
- Property access validation: The system also retrieves their authorized building list from Redis database (building id list to which the user is mapped), making sure they can only access data related to their properties within their business portfolio.
This parallel validation process facilitates more secure and appropriate access while maintaining optimal performance through Redis’s high-speed data retrieval capabilities. Redis is populated during the application load through mapping user entitlement and building mapping maintained in the database. If the user details are not found in Redis an API is invoked to replenish the Redis database.

Results and impact
CBRE’s experience with this initiative has led to enhanced operational efficiency and data reliability, directly translating into tangible business benefits:
- Cost savings and resource optimization: By reducing hours of manual effort annually per user, the business can realize substantial cost savings (for example, in labor costs, reduced overtime, or reallocated personnel). This frees up valuable user time so that the team can focus on more strategic, high-value tasks that drive building performance, innovation and growth rather than repetitive manual processes.
- Improved decision-making and risk mitigation: Delivering results with 95% accuracy for business decisions that are based on highly reliable data. This minimizes the risk of errors, leading to more informed strategies, fewer costly mistakes, and ultimately, better business outcomes.
- Increased productivity and throughput: With less time spent on manual tasks and a higher assurance of data quality, workflows can become smoother and faster. This translates to increased overall productivity and potentially higher throughput for related processes, enhancing service delivery.
Lessons learned and best practices
The following are our lessons learned and best practices based on our experience building this solution:
- Use prompt modularization: Prompt engineering is essential for optimizing application performance and maintaining consistent results. Breaking prompts into modular components helped in better prompt management, enhanced control and maintainability through streamlined version control, simplified testing and validation processes, and improved performance tracking capabilities. The modular approach to prompt design reduced token usage, which in turn decreased LLM response times and improved overall system performance. Module approach also helps in enhanced SQL generation efficiency through faster troubleshooting, reduced implementation time, and more reliable query generation, resulting in quicker resolution of edge cases and business rule updates.
- Provide accurate few shot example: For increased accuracy and consistency of SQL generation, use dynamic few shot example with modular components for seamless updates to example repository.
- Include examples covering common use cases and edge scenarios.
- Maintain a diverse set of high-quality example pairs covering various business scenarios.
- Keep examples concise and focused on specific patterns.
- Regularly update examples based on new business requirements. Remove or update outdated examples.
- Limit to top-1 or top-2 most relevant examples to manage token usage.
- Regularly validate the relevance of selected examples.
- Set up feedback loops to continuously improve example matching accuracy.
- Fine-tune similarity thresholds for optimal example matching.
- Reduce the context window: For reducing the context window size of the context passed, select only the top-N KNN fields from the schema definition along with key/mandatory fields. Only apply the dynamic context field selection for schema where high number of fields are present and increasing the context window size.
- Improve relevancy: LLM Scoring mechanism helped us in getting the right relevant set of schemas (modules). Harnessing LLM intelligence over the KNN result of relevant module helped us get the most relevant ordered results. Also consider:
- Vector similarity alone may not capture true semantic relevance.
- Top-K nearest neighbors don’t always guarantee contextual accuracy.
- Order of results may not reflect actual relevance to the query.
- Use of LLM Scoring provided a more accurate schema relevancy determination.
Conclusion
CBRE Property Management and AWS together demonstrated how innovative cloud AI solutions can unlock real business value at scale. By using AWS services and best practices, enterprises can reimagine how they access, manage, and derive insight from their data and take real action.
To learn how your organization can accelerate digital transformation with AWS, contact your AWS account team or start exploring AWS AI and data analytics services today.
Further reading on AWS services featured in this solution:
About the authors
 Lokesha Thimmegowda is a Senior Principal Software Engineer at CBRE, specializing in artificial intelligence and AWS. With four AWS certifications, including Solutions Architect Professional and AWS AI Practitioner, he excels at guiding teams through complex challenges with innovative solutions. Lokesha is passionate about designing transformative solution architectures that drive efficiency. Outside of work, he enjoys daily tennis with his daughters and weekend cricket.
Lokesha Thimmegowda is a Senior Principal Software Engineer at CBRE, specializing in artificial intelligence and AWS. With four AWS certifications, including Solutions Architect Professional and AWS AI Practitioner, he excels at guiding teams through complex challenges with innovative solutions. Lokesha is passionate about designing transformative solution architectures that drive efficiency. Outside of work, he enjoys daily tennis with his daughters and weekend cricket.
 Muppirala Venkata Krishna Kumar Principal Software Engineer at CBRE with over 18 years of expertise in leading technical teams and designing end-to-end solutions across diverse domains. A strategic technical lead with a strong command over both front-end and back-end technologies, cloud architecture using AWS, and AI/ML-driven innovations. Passionate about staying at the forefront of technology, continuously learning, and implementing modern tools to drive impactful results. Outside of work, values quality time with family and enjoys spiritual travel experiences that bring balance and inspiration.
Muppirala Venkata Krishna Kumar Principal Software Engineer at CBRE with over 18 years of expertise in leading technical teams and designing end-to-end solutions across diverse domains. A strategic technical lead with a strong command over both front-end and back-end technologies, cloud architecture using AWS, and AI/ML-driven innovations. Passionate about staying at the forefront of technology, continuously learning, and implementing modern tools to drive impactful results. Outside of work, values quality time with family and enjoys spiritual travel experiences that bring balance and inspiration.
 Maraka Vishwadev is a Senior Staff Engineer at CBRE with 18 years of experience in enterprise software development, specializing in backend–frontend technologies and AWS Cloud. He leads impactful initiatives in Generative AI, leveraging Large Language Models to drive intelligent automation, enhance user experiences, and unlock new business capabilities. He is deeply involved in architecting and delivering scalable, secure, and cloud-native solutions, aligning technology with business strategy. Vishwa balances his professional life with cooking, movies, and quality family time.
Maraka Vishwadev is a Senior Staff Engineer at CBRE with 18 years of experience in enterprise software development, specializing in backend–frontend technologies and AWS Cloud. He leads impactful initiatives in Generative AI, leveraging Large Language Models to drive intelligent automation, enhance user experiences, and unlock new business capabilities. He is deeply involved in architecting and delivering scalable, secure, and cloud-native solutions, aligning technology with business strategy. Vishwa balances his professional life with cooking, movies, and quality family time.
 Chanpreet Singh is a Senior Consultant at AWS with 18+ years of industry experience, specializing in Data Analytics and AI/ML solutions. He partners with enterprise customers to architect and implement cutting-edge solutions in Big Data, Machine Learning, and Generative AI using AWS native services, partner solutions and open-source technologies. A passionate technologist and problem solver, he balances his professional life with nature exploration, reading, and quality family time.
Chanpreet Singh is a Senior Consultant at AWS with 18+ years of industry experience, specializing in Data Analytics and AI/ML solutions. He partners with enterprise customers to architect and implement cutting-edge solutions in Big Data, Machine Learning, and Generative AI using AWS native services, partner solutions and open-source technologies. A passionate technologist and problem solver, he balances his professional life with nature exploration, reading, and quality family time.
 Sachin Khanna is a Lead Consultant specializing in Artificial Intelligence and Machine Learning (AI/ML) within the AWS Professional Services team. With a strong background in data management, generative AI, large language models, and machine learning, he brings extensive expertise to projects involving data, databases, and AI-driven solutions. His proficiency in cloud migration and cost optimization has enabled him to guide customers through successful cloud adoption journeys, delivering tailored solutions and strategic insights.
Sachin Khanna is a Lead Consultant specializing in Artificial Intelligence and Machine Learning (AI/ML) within the AWS Professional Services team. With a strong background in data management, generative AI, large language models, and machine learning, he brings extensive expertise to projects involving data, databases, and AI-driven solutions. His proficiency in cloud migration and cost optimization has enabled him to guide customers through successful cloud adoption journeys, delivering tailored solutions and strategic insights.
 Dwaragha Sivalingam is a Senior Solutions Architect specializing in generative AI at AWS, serving as a trusted advisor to customers on cloud transformation and AI strategy. With seven AWS certifications including ML Specialty, he has helped customers in many industries, including insurance, telecom, utilities, engineering, construction, and real estate. A machine learning enthusiast, he balances his professional life with family time, enjoying road trips, movies, and drone photography.
Dwaragha Sivalingam is a Senior Solutions Architect specializing in generative AI at AWS, serving as a trusted advisor to customers on cloud transformation and AI strategy. With seven AWS certifications including ML Specialty, he has helped customers in many industries, including insurance, telecom, utilities, engineering, construction, and real estate. A machine learning enthusiast, he balances his professional life with family time, enjoying road trips, movies, and drone photography.