This post was written with Bharath Suresh and Mary Law from Snowflake.
Agentic AI is a type of AI that functions autonomously, automating a broader range of tasks with minimal supervision. It combines traditional AI and generative AI capabilities to make decisions, perform tasks, and adapt to its environment without constant human intervention. These autonomous systems can plan, reason, and take actions to achieve specific goals. The following diagram, taken from A Practical Guide to AI Agents, shows the flow of these autonomous actions.
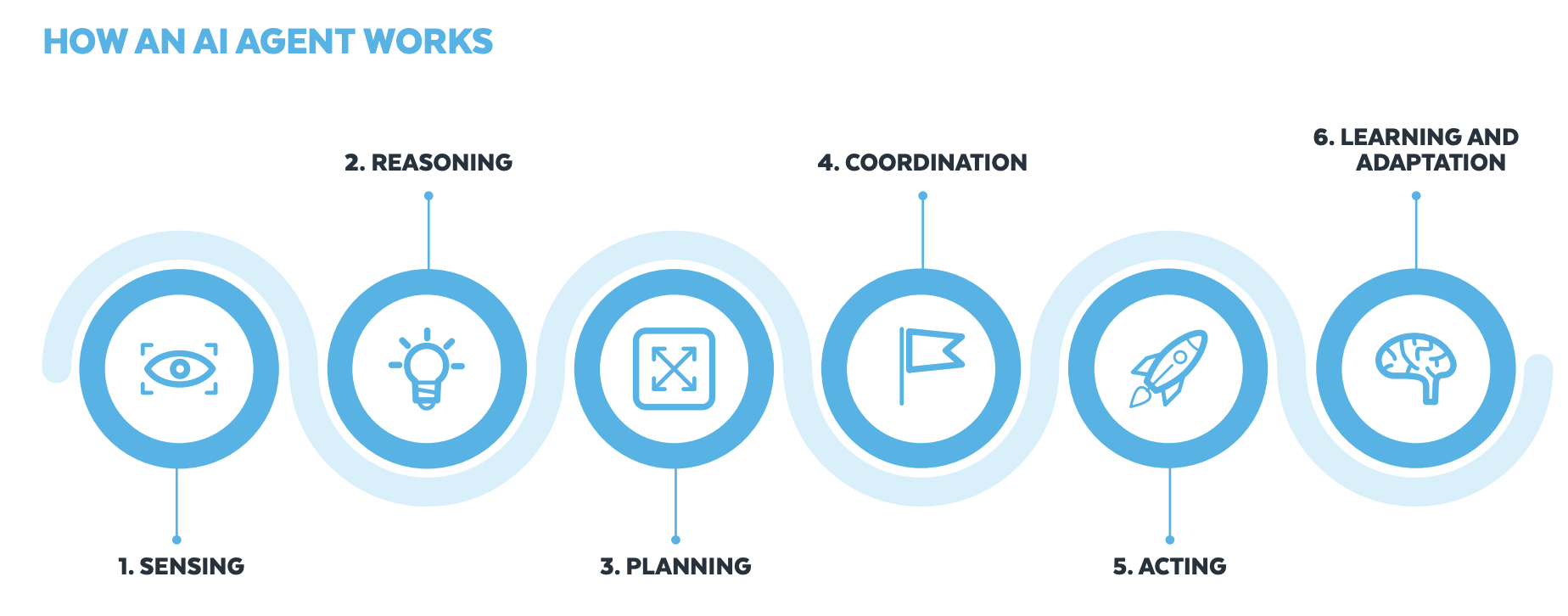
In this post, we cover how you can use tools from Snowflake AI Data Cloud and Amazon Web Services (AWS) to build generative AI solutions that organizations can use to make data-driven decisions, increase operational efficiency, and ultimately gain a competitive edge.
Snowflake is an AWS Competency Partner with multiple AWS Competencies including Generative AI, Data & Analytics, Machine Learning, and Retail independent software vendor (ISV). Snowflake is available in the AWS Marketplace. Snowflake builds tools for every organization to mobilize their data, unify siloed data, and discover and securely share data. Snowflake brings AI to governed data, enabling teams to run analytical workflows on unstructured data, develop agentic applications, and train models using both structured and unstructured data with minimal operational overhead and end-to-end governance. Snowflake is a strong AWS Partner, available in over 20 AWS Regions, offering a wide range of support and integration with AWS services. This includes features such as AWS PrivateLink for secure connectivity and Snowpipe for automated data loading from Amazon Simple Storage Service (Amazon S3), AWS Glue for data cataloging, and model development with Amazon SageMaker. Snowflake has received Amazon SageMaker Ready Product service validation.
The business challenge
Traditional vehicle insurance claim processing involves several stages, from manually validating documents such as driver’s licenses, claim forms, and car damage images. This manual workflow is often siloed and prone to errors. In this post, we demonstrate an agentic AI workflow that automates this end-to-end process. This sample demonstrates the art of the possible while improving operational efficiency and scalability, reducing human errors, and enabling informed decision-making. The sample solution involves the following key services:
- Snowflake – The AI Data Cloud. A unified platform that eliminates data silos and makes data and AI straightforward, connected, and trusted.
- Snowflake Document AI – AI feature that uses Arctic-TILT, a proprietary large language model (LLM), to extract data from documents. Document AI is best used to turn unstructured data from documents into structured data in tables. Refer to Document AI availability.
- Streamlit in Snowflake is an open source Python library that makes it seamless to create and share custom web apps for machine learning (ML) and data science. By using Streamlit, you can quickly build and deploy powerful data applications. For additional use cases on building dashboards, data tools, and artificial intelligence and machine learning (AI/ML), refer to Streamlit in Snowflake demos.
- Amazon Bedrock – A fully managed service to build generative AI applications, offering a choice of high-performing foundation models (FMs) from leading AI companies. Amazon Nova Lite is a low-cost multimodal model that is lightning fast for processing image, video, and text input.
- LangGraph – A stateful, orchestration framework that brings added control to agent workflows.
The demonstration of the solution is shown in the following video.

Solution overview
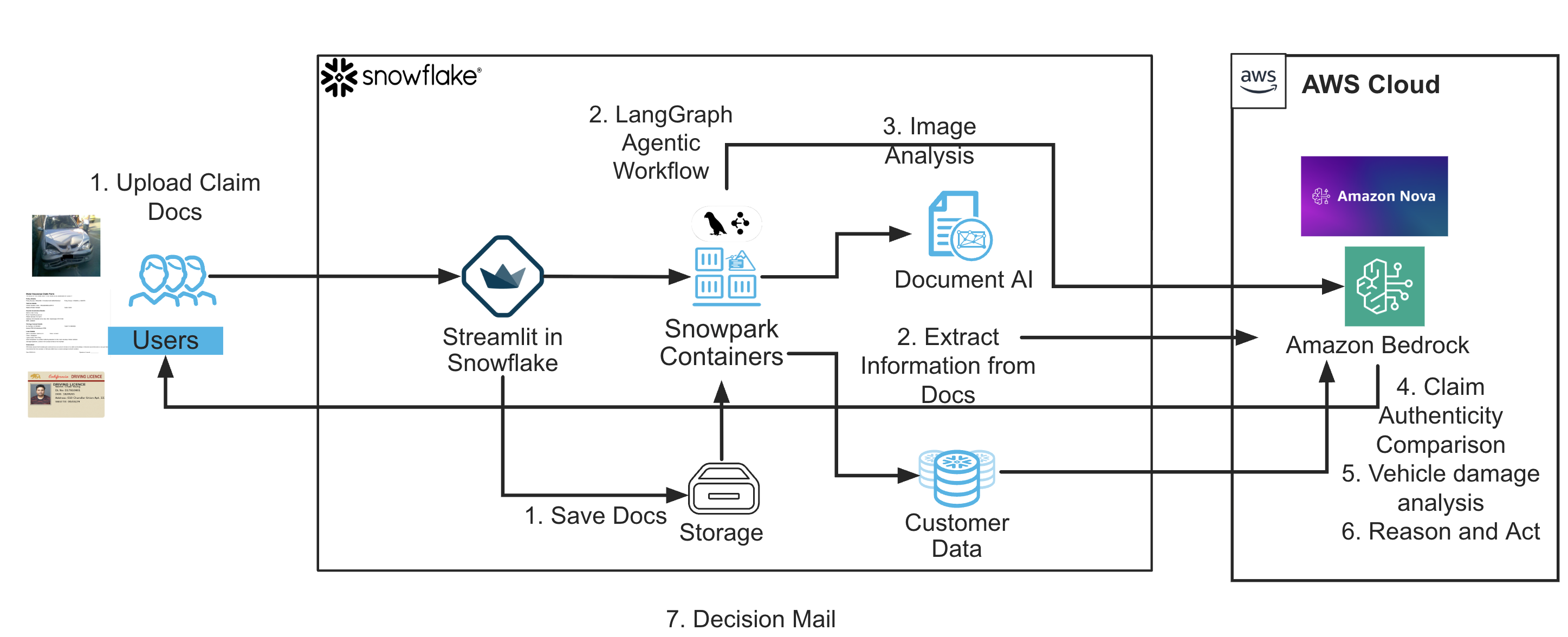
This solution implements a fully autonomous, explainable workflow for vehicle insurance claim processing using an agentic AI architecture. At its core, the pipeline combines structured document extraction, multimodal image analysis, policy validation, and natural language generation, chained together using a stateful LangGraph workflow and surfaced through an interactive Streamlit UI. Here’s how the end-to-end flow works at a high level:
- The user uploads three essential artifacts:
- A scanned driver’s license (DL)
- A filled-out claim form (PDF or image)
- A car damage photo
- The uploaded license and claim documents are processed using Snowflake’s Cortex Document AI models (
LICENSE_DATAandCLAIMS_DATA). These models extract structured fields such as name, DL number, vehicle details, and the incident date, all with zero-shot or fine-tuned inference. - The car damage photo is analyzed by Amazon Nova Lite through Amazon Bedrock. The image and a text prompt are passed to the model, which returns a professional summary of visible damage, car type, make, and color. This adds unstructured image insight into the reasoning process.
- Extracted values from the license, claim, and image are cross-checked for consistency (for example, name match, DL number, vehicle color) and verified against Snowflake policy records (for example, customer profile, VIN, policy expiration). This confirms the claim is authentic and eligible.
- The incident date from the claim is compared to the policy end date retrieved from Snowflake. Claims outside the policy window are flagged automatically.
- A decision is made based on match accuracy and policy status. The system compiles the comparison summary and generates a customer-facing decision email using natural language generation in Amazon Nova Lite.
- All stages are linked as nodes in a LangGraph state machine, where each node processes the shared workflow state and passes it forward. This structure provides modularity, auditability, and deterministic control.
- The final outputs—including workflow steps, decision status, matched values, and the email—are displayed to the user in real time through a Streamlit UI. A debugging expander reveals full raw JSON data from each extraction stage.
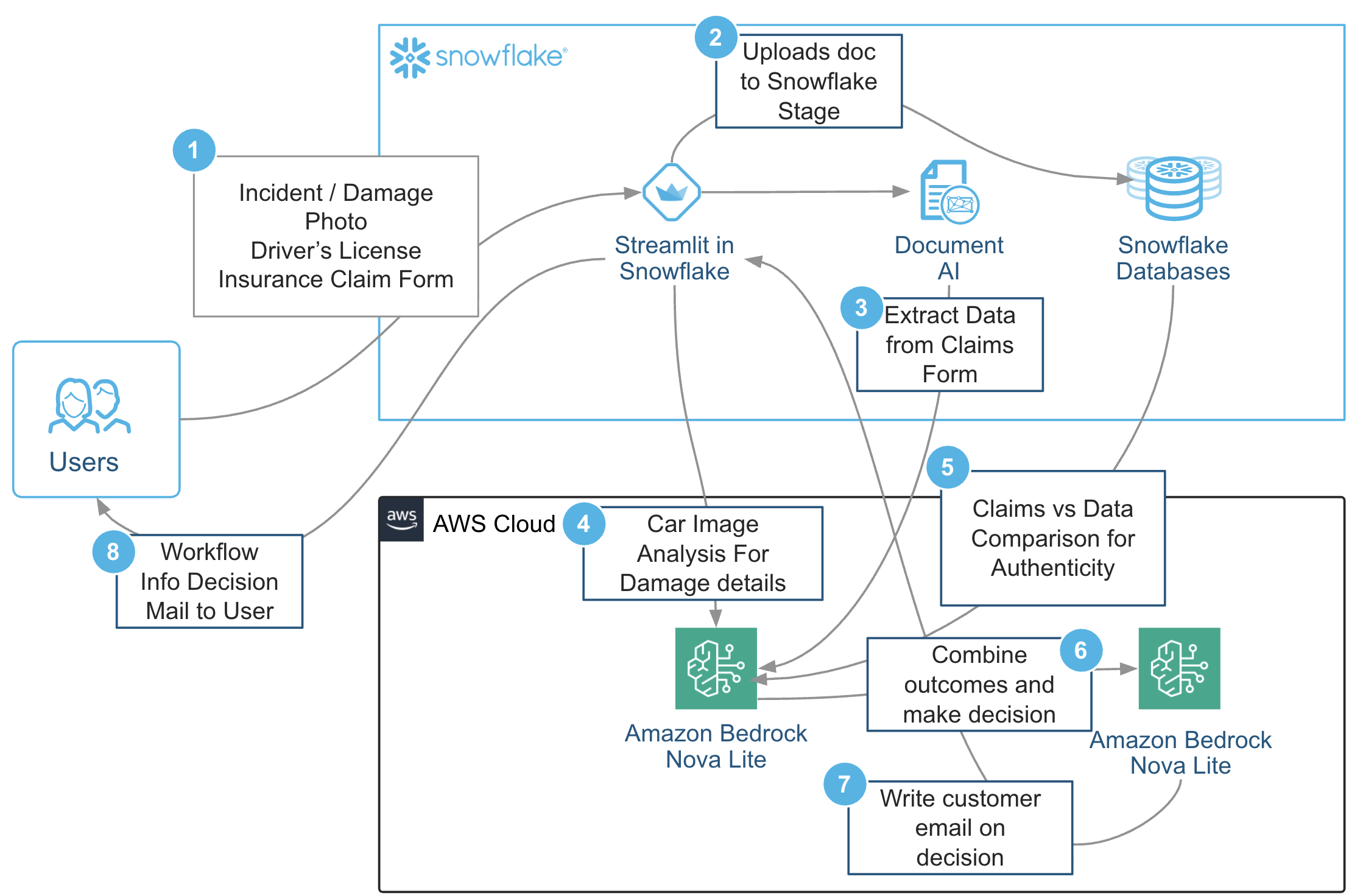
This solution showcases how multiple AI components—document understanding, multimodal reasoning, and generation of custom models—can be tightly integrated into a single pipeline that autonomously perceives, reasons, and acts. The solution workflow follows these steps:
- The user submits all the documents to Streamlit apps.
- The user uploads documents such as incident photos, driver’s licenses, and insurance claim forms to Snowflake Stage.
- Snowflake Document AI is used to extract data from the insurance claim form.
- Amazon Nova Lite in Amazon Bedrock is used to compare the extracted claims data for authenticity.
- Amazon Nova Lite in Amazon Bedrock analyzes car images to identify damage details.
- The system combines the outcomes from the previous steps to decide the claim.
- An email is drafted to the customer informing them of the decision.
- Workflow information and the decision are sent to the user through email.
These steps are shown in the following diagram.
Prerequisites
To implement the solution provided in this post, you need the following:
- Snowflake account – Active account with permissions, Snowflake SQL or Snowsight familiarity, and Cortex Document AI enabled.
- AWS account – Active account with Amazon Bedrock access, including access to Amazon Nova Lite, and configured AWS credentials.
- Python environment – Python 3.x and required packages installed.
- GitHub access – Clone the provided GitHub repository. This repository provides a comprehensive understanding of how each component integrates and functions together seamlessly through a LangGraph-powered state machine, from document upload and extraction to validation.
- Document preparation – Sample driver’s license images, claim form PDFs, and car damage images with relevant data.
- Snowflake data setup – A
`customer_policy_view`table or view with policyholder data (customer ID,VIN, andPOLICY_END) and sample data. - Snowflake Document AI model builds – Two models in Snowsight for licenses and claims, trained and published for prediction.
- Amazon Bedrock configuration – AWS credentials set up for Python to access FMs in Amazon Bedrock models.
Documents used
To simulate a realistic insurance claim scenario for this agentic AI workflow, we prepared three representative input documents that align with how real users might file claims. The dataset includes:
- A driver’s license (DL) showing name, DL number, date of birth, address, and license validity date, as shown in the following image

- A completed claim form (PDF) capturing customer ID, vehicle details, accident description, and incident date, as shown in the following image

- Photographs showing damage to the vehicle, as shown in the following image


The car damage images used in this are sourced from car damage dataset.
Document processing
This sample solution uses Snowflake Document AI, powered by the proprietary Arctic-TILT LLM, to extract information from uploaded documents with impressive flexibility. For information about getting started with Document AI, visit Setting up Document AI.
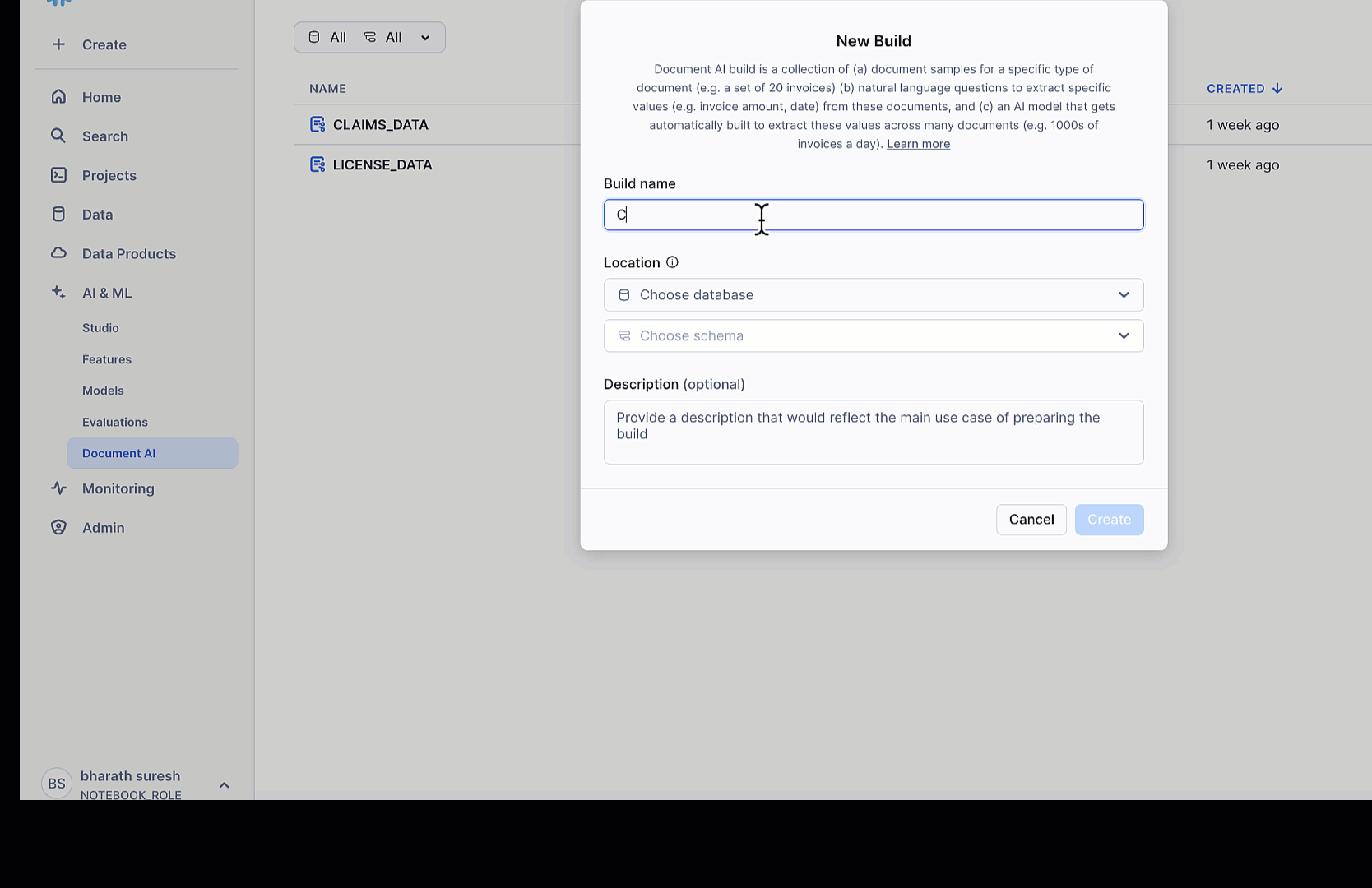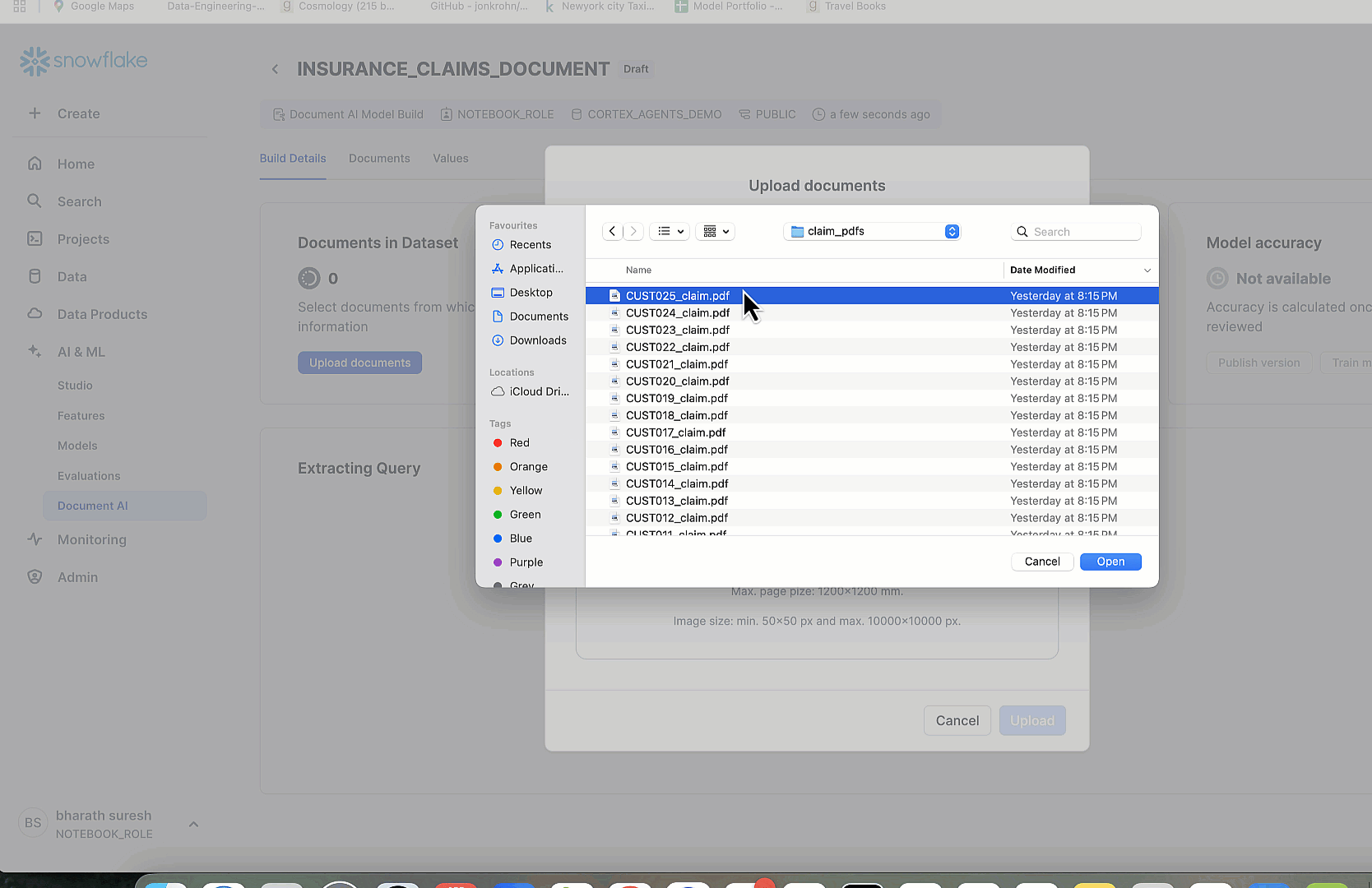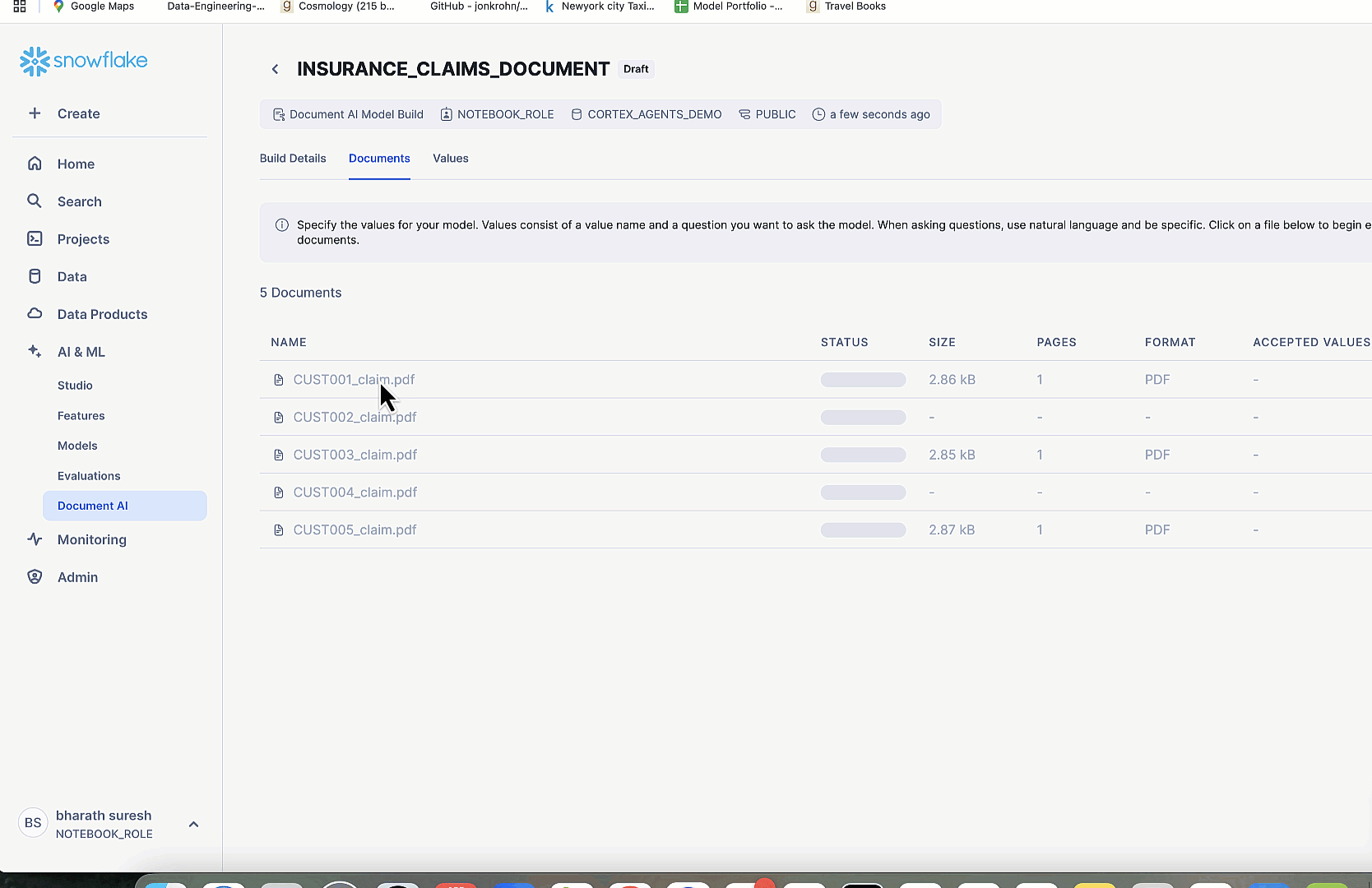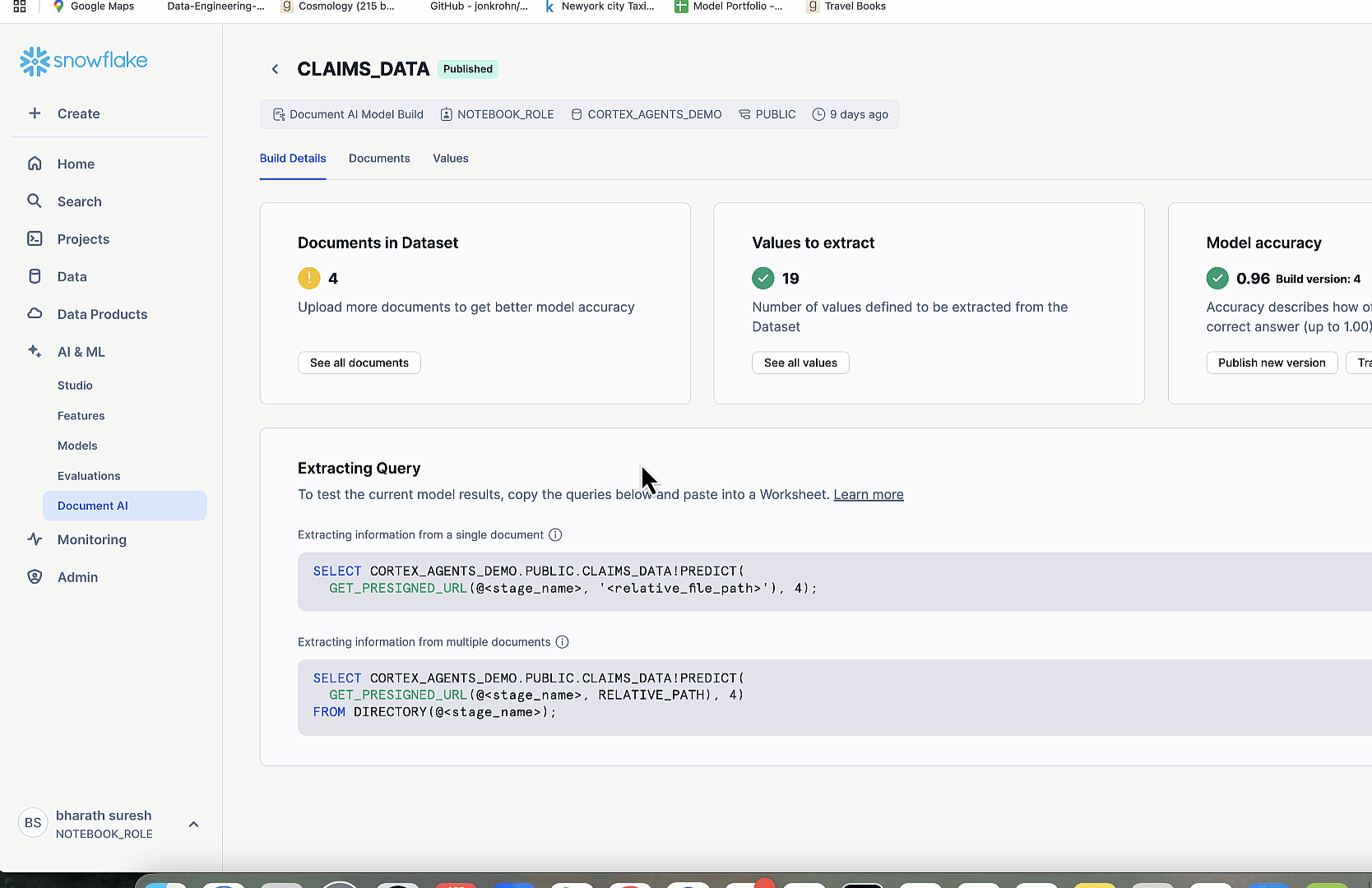
We created two Document AI model builds in Snowsight—one for driver’s licenses and one for claim forms—using Snowflake’s DOCUMENT_INTELLIGENCE class powered by the Arctic-TILT LLM. For each model, we uploaded sample documents, defined extraction fields using natural language prompts (for example, “What is the license number?”), reviewed confidence-scored results, and published the models for use using the MODEL_NAME!PREDICT(GET_PRESIGNED_URL(...)) SQL syntax. This enabled zero-shot extraction in the pipeline without requiring retraining for every new file. The following diagram shows the workflow for document processing.

Uploaded documents go through specialized AI-driven processing. Licenses are parsed using LICENSE_DATA!PREDICT for fields such as name and DL number. Claims are parsed using CLAIMS_DATA!PREDICT for vehicle and incident details (including inferred vehicle color).
Car images are analyzed by the Amazon Nova Lite model on Amazon Bedrock to extract structured damage details. This multi-modal extraction layer transforms raw inputs into structured insights for downstream decisioning.
Preparing the Document AI models in Snowsight
To extract information from unstructured documents such as driver’s licenses and insurance claim forms, we use Snowflake’s Document AI. We’ve created two model builds—LICENSE_DATA and CLAIMS_DATA—each designed to extract specific fields using natural language prompts. After signing into Snowsight with the appropriate role, we choose AI & ML and Document AI in the left navigation pane. Then we create a new build and upload sample documents.
Each file passes through optical character recognition (OCR), after which we define fields by pairing value names with extraction questions. We then receive confidence-scored answers, which we review and confirm. When accuracy is satisfactory, we publish the models, making them callable from SQL using the MODEL_NAME!PREDICT(GET_PRESIGNED_URL(...)) syntax. For improved precision, we have the option to fine-tune the models using reviewed documents. This setup enables robust, zero-shot field extraction from real-world forms—no custom ML pipeline required.
After creating and training the Document AI models in Snowsight (for example, `LICENSE_DATA` and `CLAIMS_DATA`) and ensuring they’re published and ready for predictions using `MODEL_NAME!PREDICT(GET_PRESIGNED_URL(...))`, we transition to using Python code to process the rest of the workflow. The Python code will handle the orchestration, data retrieval, LLM interactions, and decision-making steps required to complete the insurance claim processing pipeline.
The following video shows this process.
Amazon Nova Lite for car damage analysis
To evaluate vehicle damage from incident images, we use Amazon Nova Lite in AWS Bedrock, a high-performance, low-latency multimodal FM. Nova Lite enables our agentic workflow to interpret unstructured image data—such as car photos—using a single natural language prompt, without the need for specialized computer vision models.
After the image is uploaded through the Streamlit interface, it’s encoded in base64 and wrapped in a multimodal prompt. We simulate a professional damage inspection scenario by sending both the image and a textual instruction to the model. Here’s the actual logic used in our backend:
The model returns a natural language response, such as:
We store this summary as part of the car object in the shared workflow state:
By using the multimodal capabilities in Amazon Nova Lite, we significantly reduce the complexity of image processing and avoid the need for training and maintaining separate image recognition models. This step adds visual intelligence to the agentic pipeline—enabling more complete and human-aligned assessments of insurance claims.
Cross-document comparison and policy validation with Amazon Nova
After extracting data from the driver’s license, claim form, and car image, the agentic AI workflow verifies the consistency and authenticity of the information. This is done through cross-document comparison and a policy validation check against Snowflake’s records.
First, we identify the customer using the name extracted from the claim form. We query a Snowflake view (customer_policy_view) to retrieve the associated customer ID. Then, we join this view with the DRIVER_LICENSES table to fetch reference fields such as color, make and model, date of birth, license number, and the policy end date.
Here’s the actual SQL logic used in the workflow:
Next, we compare each extracted value from the documents with its counterpart from the database. Fields compared include:
full_namedl_nodobvehicle_colormake_model
Each comparison returns a match status (true or false) and both the extracted and reference values so we can trace mismatches clearly. The comparison dictionary is structured like this:
We then validate the policy’s active status by comparing the incident date from the claim against the policy end date from Snowflake:
This dual-layer validation helps make the claim both factually accurate and legally valid. Critical mismatches (such as an invalid DL number or expired policy) lead to automatic rejection, whereas verified matches and in-policy incidents result in acceptance.
By performing this reasoning step entirely in Python using structured comparison logic, we maintain full transparency, flexibility, and auditability—crucial for enterprise insurance systems.
Autonomous reasoning and claim decision with Amazon Nova
With all relevant data extracted and validated—across the driver’s license, claim form, car photo, and policy database—the final step in the workflow is to reason over the full context and generate a clear, professional claim decision. This is where Amazon Nova Lite steps in again, this time as a logic processor and natural language generator.
We craft a structured prompt that provides Amazon Nova Lite with all the evidence gathered so far, including field-level comparison results, the policy end date, the date of the incident, and a computed decision flag (accepted or rejected). Here’s how the decision logic is computed in Python: decision = "✅ Claim Accepted" if valid else "❌ Claim Rejected due to expired policy"
We then prepare a human-readable reasoning prompt that summarizes the situation:
This prompt is passed to Amazon Nova Lite using the Amazon Bedrock Runtime API. Nova Lite interprets the full context and generates a clear message tailored to the customer:
The response might look like this:
This output is stored in the workflow state alongside the structured decision and comparison result. For all outcomes, in the final step in our agentic application, the system will automatically generate a customer-ready message without human involvement.
By using Amazon Nova Lite for multimodal inputs and autonomous decision communication, we close the loop of an intelligent, self-reasoning workflow that mimics the judgment and empathy of a human insurance adjuster, and it can do this at scale.
Final output example
After processing the uploaded documents, analyzing the car image, validating extracted fields, and confirming policy eligibility, the agentic AI workflow produces a structured and interpretable output that includes comparison results across documents and Snowflake records, a claim decision (accepted or rejected), and a customer-facing email generated by Amazon Nova Lite. Here’s an example of a complete output from a successful claim:
This output showcases the full power of the pipeline, with ground truth from Snowflake, intelligent extraction with Document AI, multimodal reasoning using Amazon Nova Lite, and decision explanation in natural language.
The structured format makes it straightforward to audit, log, or integrate with downstream systems such as customer relationship management (CRM) systems, email workflows, or insurance management platforms. More importantly, it closes the loop on trustable, explainable AI in production.
How the agentic AI workflow is automated
The entire vehicle insurance claim processing pipeline is implemented as an agentic AI workflow, in which each stage observes inputs, applies reasoning, makes decisions using LLMs, and forwards context to the next stage. This is orchestrated using LangGraph, a stateful workflow engine that treats each task as a modular node and passes a shared state throughout the graph.
At the heart of this automation is a LangGraph state machine, where major processing stages such as document extraction, car image analysis, and final claim decision are defined as nodes. These nodes are connected through directed edges to form a sequential and explainable pipeline:
Each function takes in the current state, performs its designated task—such as running LLM inference or querying Snowflake—and returns updated state information. Here’s how each step contributes:
- Document upload and staging – The
upload_allnode handles file uploads from the Streamlit frontend and stages them into a Snowflake internal stage using:
session.file.put(local_path, STAGE_NAME, overwrite=True)
- Document extraction with Document AI – Both
extract_dlandextract_claimnodes invoke Snowflake Document AI using zero-shot prediction with presigned URLs:
sql = f"SELECT LICENSE_DATA!PREDICT(GET_PRESIGNED_URL(@doc_ai_stage, '{path}'), 2)"
- Multimodal car image analysis (Amazon Nova Lite) – The
extract_carnode sends a structured prompt and the Base64-encoded image to Amazon Nova Lite. Although the reference version returns detailed JSON fields such as make and model, the current implementation uses natural language summaries for damage inspection. - Cross-document reasoning and comparison – The
compare_and_emailnode performs the reasoning phase by comparing extracted values from:- Driver’s license and claim (name, DL number)
- Car image and claim (vehicle color, make and model)
- Claim and Snowflake policy (policy dates)
- These are organized into a structured prompt and passed to Amazon Nova Lite. The output is parsed into a
comparisondictionary for downstream decision-making. - Policy validity check (Snowflake SQL) – Still within the same node, a SQL query retrieves policy records:
SELECT VEHICLE_NUMBER, POLICY_END FROM customer_policy_view WHERE customer_id = '{customer_id}'
- It then checks if the claim’s incident date falls within the policy’s active period.
- Claim decision and email generation – A claim is either accepted or rejected based on field-level and date-level validation:
decision = "✅ Claim Accepted" if incident_date <= policy_end_date else "❌ Claim Rejected"
- This result, along with the comparison context, is used to construct a customer-facing email using Amazon Nova Lite.
- Agentic state chaining – The flow is linked through directed edges in the graph:
Each node augments the state with new observations and decisions, enabling the pipeline to autonomously perceive, reason, and act—the hallmarks of an agentic AI system.
Interactive frontend with Streamlit
To make the workflow accessible and intuitive, we built a clean user-facing frontend using Streamlit, a popular open source Python framework for rapid UI prototyping and data apps. Streamlit app users can upload their claim-related documents and get real-time outputs including claim validation, policy decision, and a generated customer-facing email.
The Streamlit interface starts by requesting three required documents: a scanned driver’s license, the claim form (PDF or image), and a car damage photo. These are captured through file_uploader widgets with format restrictions to ensure valid input:
After all documents are uploaded, users choose a button to initiate the backend pipeline, which calls the LangGraph-powered function run_claim_processing_workflow():
A spinner is shown while the workflow executes, and errors are surfaced immediately to the UI for troubleshooting.
When the workflow is complete, the UI displays the results in structured sections for workflow steps that were completed, a field-level comparison output, a policy validity result, and a
final customer email generated by Amazon Nova Lite. These results are rendered using st.markdown() and st.json() for easy interpretation:
For developers or quality assurance (QA) teams, a collapsible section provides access to raw JSON outputs extracted from the driver’s license, claim form, and car image:
This provides full transparency across all AI-driven decisions and supports auditability, a critical feature in regulated industries such as insurance.
Cleanup
After the demo, perform the following cleanup steps:
- Snowflake cleanup:
- (Optional) Truncate or drop the
`customer_policy_view`table or view if it was created solely for the demo. - Consider deleting the Document AI models (`LICENSE_DATA` and `CLAIMS_DATA`) if they’re no longer needed.
- Remove files uploaded to the internal stage (
`doc_ai_stage`)
- (Optional) Truncate or drop the
- AWS cleanup:
- If temporary AWS resources were created, delete them. Amazon Bedrock model access typically doesn’t require cleanup, but temporary AWS Identity and Access Management (IAM) roles or policies should be removed if they were created.
Following these setup and cleanup steps provides a smooth demo experience and a clean environment afterward.
Conclusion
This project demonstrates the potential of agentic AI workflows in managing real-world, document-centric processes, using vehicle insurance claim validation as a case study. The system executes complex workflows across multiple tasks and data streams, orchestrating operations without constant human supervision. By integrating Snowflake’s Document AI, the multimodal and reasoning models of Amazon Bedrock and Amazon Nova Lite, and orchestration by LangGraph, we’ve created a robust, explainable, and production-ready solution capable of autonomous perception, reasoning, and action.
From structured document extraction to visual damage understanding, cross-document comparison, policy lookup, and natural language email drafting — each step of the pipeline behaves as a specialized agent contributing to the overall goal. LangGraph’s stateful workflow design makes it easy to extend this further with more capabilities such as fraud detection, document classification, or vendor coordination.
This isn’t merely an insurance app, it’s a template for building next-generation AI systems that reason across modalities, interact with enterprise data, and execute with autonomy. These modular, explainable workflows will be essential for implementing AI in real-world business processes as agentic AI becomes more prevalent. Agentic AI has the potential to increase efficiency, improve decision-making, accelerate time to market, raise customer satisfaction, and create more opportunities for innovation.
Resources
- Refer to Amazon Nova Foundation Models for more information and to get started with Amazon Nova.
- Try Snowflake for a no cost 30-day trial in AWS Marketplace. Watch this AWS and Snowflake Better Together webinar.
- To learn more and get hands-on resources to start using Snowflake’s generative AI, visit Snowflake for AI and download “A Practical Guide to AI Agents”.
About the Authors
 Bharath Suresh is a Senior Solutions Engineer at Snowflake and former Amazon Web Services (AWS) and IBM Architect with over 15 years of experience in cloud architecture, data platforms, and AI-driven solutions across global enterprises. At Snowflake, he empowers customers to modernize data and AI workloads, with a focus on agentic workflows, governance, and multi-cloud transformation.
Bharath Suresh is a Senior Solutions Engineer at Snowflake and former Amazon Web Services (AWS) and IBM Architect with over 15 years of experience in cloud architecture, data platforms, and AI-driven solutions across global enterprises. At Snowflake, he empowers customers to modernize data and AI workloads, with a focus on agentic workflows, governance, and multi-cloud transformation.
 Mary Law is an APJ Partner Tech Lead at Snowflake, the AI Data Cloud. Her background includes leading the APJ Analytics Acceleration Lab at AWS and Data & AI specialist roles at Microsoft. This journey through different cloud ecosystems gives Mary unique insights into solving complex data challenges. She is passionate about helping partners develop solutions that deliver real business value.
Mary Law is an APJ Partner Tech Lead at Snowflake, the AI Data Cloud. Her background includes leading the APJ Analytics Acceleration Lab at AWS and Data & AI specialist roles at Microsoft. This journey through different cloud ecosystems gives Mary unique insights into solving complex data challenges. She is passionate about helping partners develop solutions that deliver real business value.
 Amelia Mantle is an Associate Solutions Architect at Amazon Web Services (AWS). With a background in data science, Amelia continues to help customers develop AI/ML solutions in the cloud. She serves as a trusted AI advisor to organizations navigating their digital transformation journey, working closely with AWS partners and customers to architect and implement innovative AI services.
Amelia Mantle is an Associate Solutions Architect at Amazon Web Services (AWS). With a background in data science, Amelia continues to help customers develop AI/ML solutions in the cloud. She serves as a trusted AI advisor to organizations navigating their digital transformation journey, working closely with AWS partners and customers to architect and implement innovative AI services.