Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies through a single API, along with capabilities to build generative AI applications with security, privacy, and responsible AI.
Batch inference in Amazon Bedrock is for larger workloads where immediate responses aren’t critical. With a batch processing approach, organizations can analyze substantial datasets efficiently, with significant cost advantages: you can benefit from a 50% reduction in pricing compared to the on-demand option. This makes batch inference particularly valuable for handling extensive data to get inference from Amazon Bedrock FMs.
As organizations scale their use of Amazon Bedrock FMs for large-volume data processing, implementing effective monitoring and management practices for batch inference jobs becomes an important focus area for optimization. This solution demonstrates how to implement automated monitoring for Amazon Bedrock batch inference jobs using AWS serverless services such as AWS Lambda, Amazon DynamoDB, and Amazon EventBridge, reducing operational overhead while maintaining reliable processing of large-scale batch inference workloads. Through a practical example in the financial services sector, we show how to build a production-ready system that automatically tracks job status, provides real-time notifications, and maintains audit records of processing activities.
Solution overview
Consider a scenario where a financial services company manages millions of customer interactions and data points, including credit histories, spending patterns, and financial preferences. This company recognized the potential of using advanced AI capabilities to deliver personalized product recommendations at scale. However, processing such massive datasets in real time isn’t always necessary or cost-effective.
The solution presented in this post uses batch inference in Amazon Bedrock with automated monitoring to process large volumes of customer data efficiently using the following architecture.
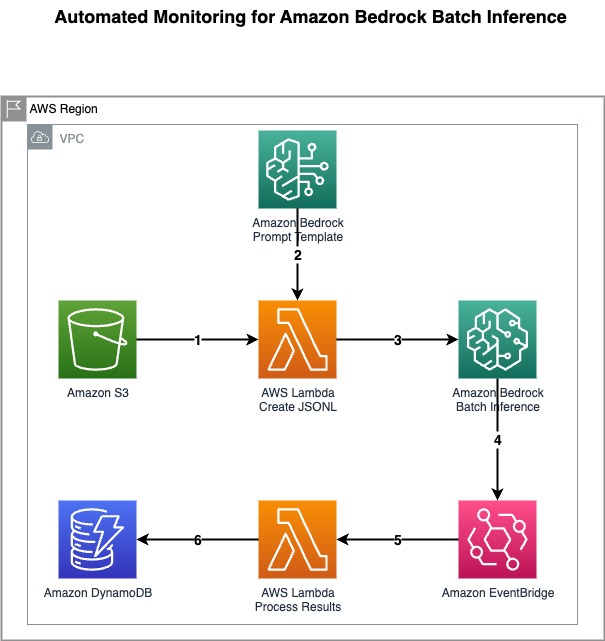
This architecture workflow includes the following steps:
- The financial services company uploads customer credit data and product data to be processed to an Amazon Simple Storage Service (Amazon S3) bucket.
- The first Lambda function reads the prompt template and data from the S3 bucket, and creates a JSONL file with prompts for the customers along with their credit data and available financial products.
- The same Lambda function triggers a new Amazon Bedrock batch inference job using this JSONL file.
- In the prompt template, the FM is given a role of expert in recommendation systems within the financial services industry. This way, the model understands the customer and their credit information to intelligently recommend most suitable products.
- An EventBridge rule monitors the state changes of the batch inference job. When the job completes or fails, the rule triggers a second Lambda function.
- The second Lambda function creates an entry for the job with its status in a DynamoDB table.
- After a batch job is complete, its output files (containing personalized product recommendations) will be available in the S3 bucket’s
inference_resultsfolder.
This automated monitoring solution for Amazon Bedrock batch inference offers several key benefits:
- Real-time visibility – Integration of DynamoDB and EventBridge provides real-time visibility into the status of batch inference jobs, enabling proactive monitoring and timely decision-making
- Streamlined operations – Automated job monitoring and management minimizes manual overhead, reducing operational complexities so teams can focus on higher-value tasks like analyzing recommendation results
- Optimized resource allocation – Metrics and insights about token count and latency stored in DynamoDB help organizations optimize resource allocation, facilitating efficient utilization of batch inference capabilities and cost-effectiveness
Prerequisites
To implement this solution, you must have the following:
- An active AWS account with appropriate permissions to create resources, including S3 buckets, Lambda functions, and Amazon Bedrock resources.
- Access to your selected models hosted on Amazon Bedrock. Make sure the selected model has been enabled in Amazon Bedrock.
Additionally, make sure to deploy the solution in an AWS Region that supports batch inference.
Deploy solution
For this solution, we provide an AWS CloudFormation template that sets up the services included in the architecture, to enable repeatable deployments. This template creates the following resources:
- An S3 bucket to store the input and output
- AWS Identity and Access Management (IAM) roles for Lambda functions, EventBridge rule, and Amazon Bedrock batch inference job
- Amazon Bedrock Prompt Management template
- EventBridge rule to trigger the Lambda function
- DynamoDB table to store the job execution details
To deploy the CloudFormation template, complete the following steps:
- Sign in to the AWS Management Console.
- Open the template directly on the Create stack page of the CloudFormation console.
- Choose Next and provide the following details:
- For Stack name, enter a unique name.
- For ModelId, enter the model ID that you need your batch job to run with. Only Anthropic Claude family models can be used with the CloudFormation template provided in this post.
- Add optional tags, permissions, and other advanced settings if needed.
- Review the stack details, select I acknowledge that AWS CloudFormation might create AWS IAM resources, and choose Next.
- Choose Submit to initiate the deployment in your AWS account.
The stack might take several minutes to complete.
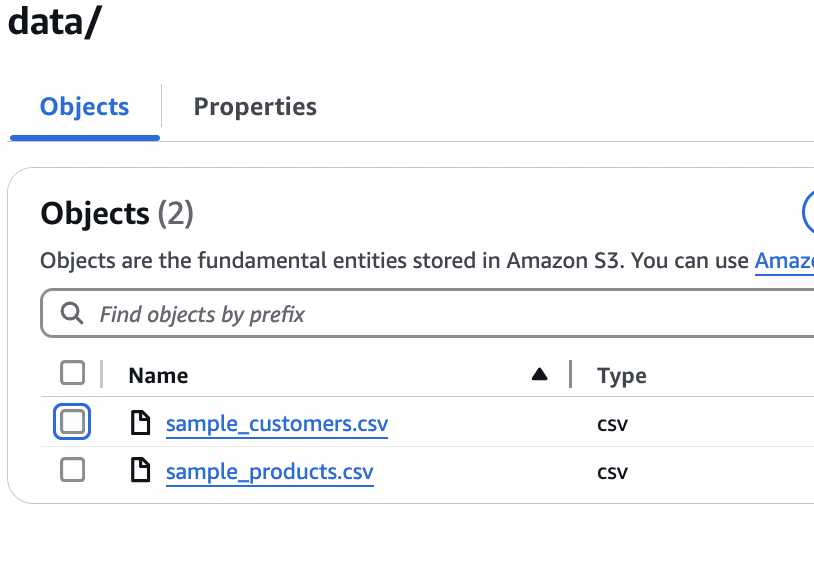
- Choose the Resources tab to find the newly created S3 bucket after the deployment succeeds.
- Open the S3 bucket and confirm that there are two CSV files in your data folder.
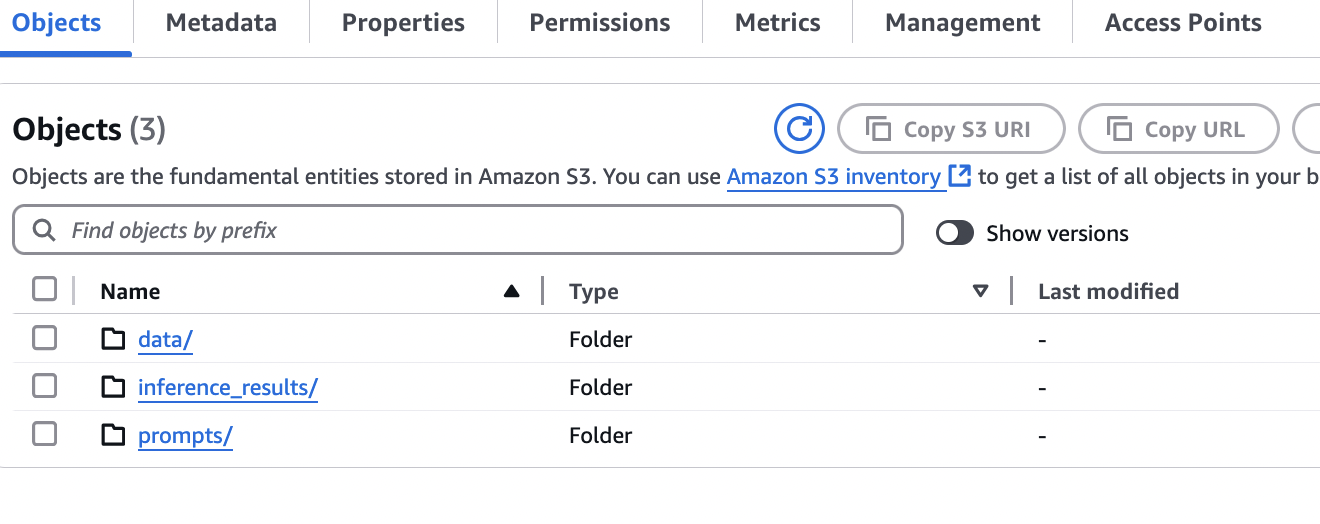
- On the Amazon S3 console, go to the data folder and create two more folders manually. This will prepare your S3 bucket to store the prompts and batch inference job results.
- On the Lambda console, choose Functions in the navigation pane.
- Choose the function that has
create-jsonl-filein its name.
- On the Test tab, choose Test to run the Lambda function.
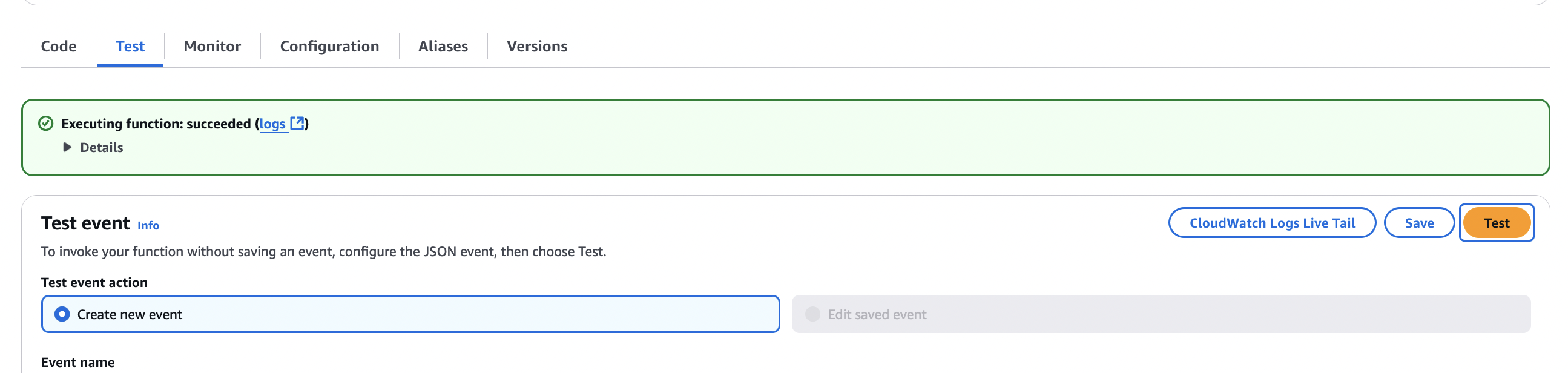
The function reads the CSV files from the S3 bucket and the prompt template, and creates a JSONL file with prompts for the customers under the prompts folder of your S3 bucket. The JSONL file has 100 prompts using the customers and products data. Lastly, the function submits a batch inference job with the CreateModelInvocationJob API call using the JSONL file. - On the Amazon Bedrock console, choose Prompt Management under Builder tools in the navigation pane.
- Choose the
finance-product-recommender-v1prompt to see the prompt template input for the FM. - Choose Batch inference in the navigation pane under Inference and Assessment to find the submitted job.
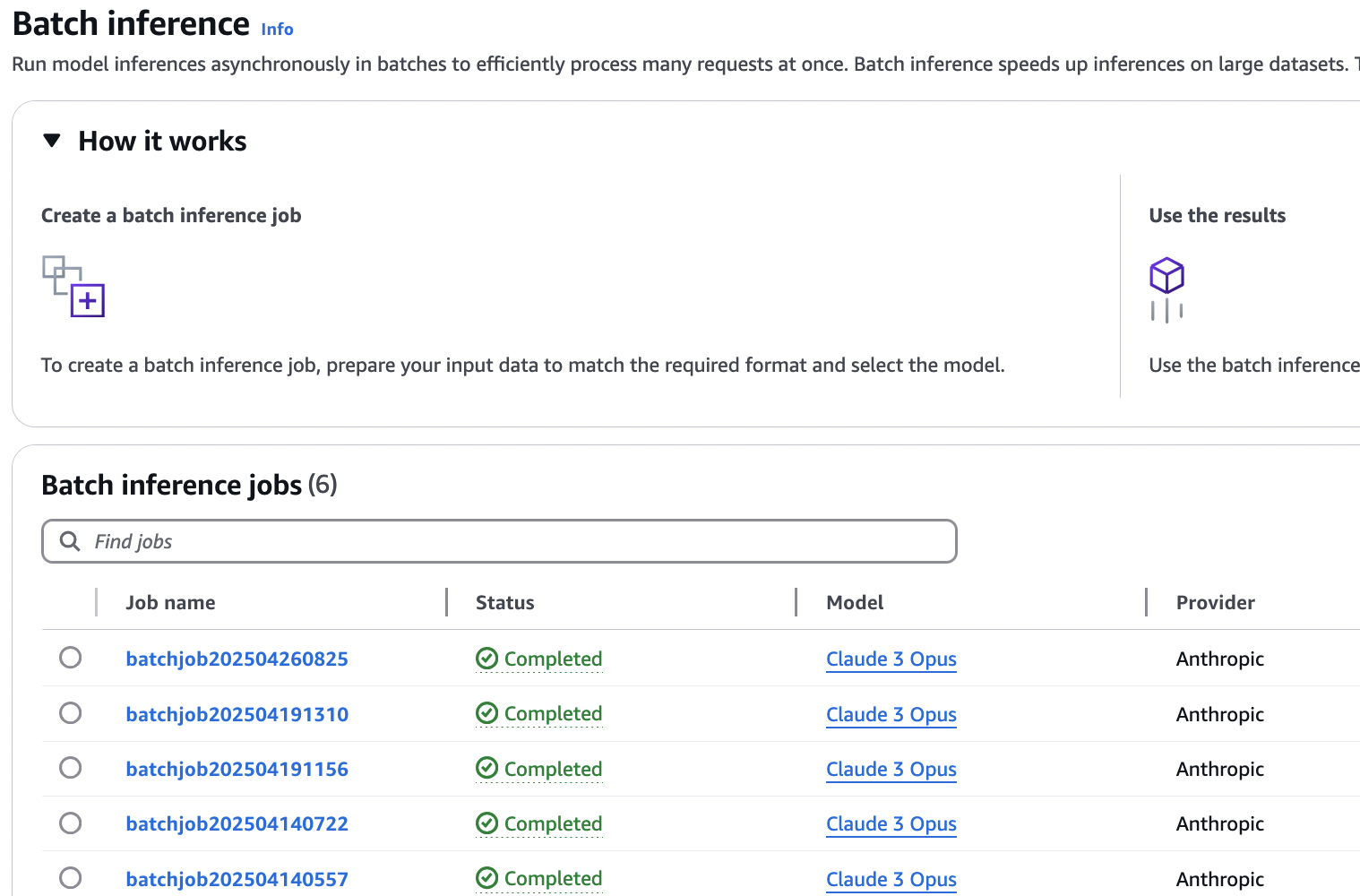
The job progresses through different statuses: Submitted, Validating, In Progress, and lastly Completed, or Failed. You can leave this page and check the status after a few hours.
The EventBridge rule will automatically trigger the second Lambda function with event-bridge-trigger in its name on completion of the job. This function will add an entry in the DynamoDB table named bedrock_batch_job_status with details of the execution, as shown in the following screenshot.
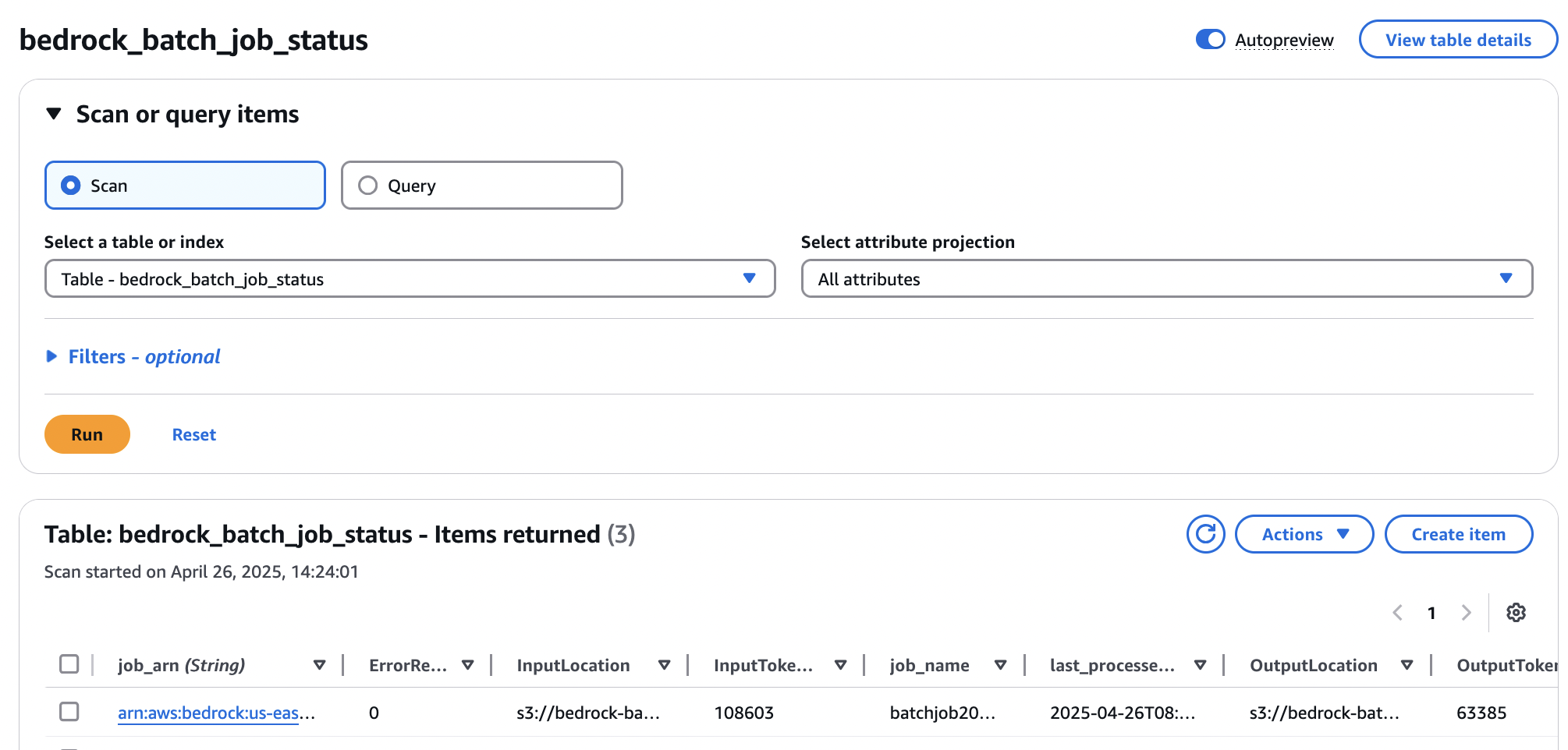
This DynamoDB table functions as a state manager for Amazon Bedrock batch inference jobs, tracking the lifecycle of each request. The columns of the table are logically divided into the following categories:
- Job identification and core attributes (
job_arn,job_name) – These columns provide the unique identifier and a human-readable name for each batch inference request, serving as the primary keys or core attributes for tracking. - Execution and lifecycle management (
StartTime,EndTime,last_processed_timestamp,TotalDuration) – This category captures the temporal aspects and the overall progression of the job, allowing for monitoring of its current state, start/end times, and total processing duration.last_processed_timestampis crucial for understanding the most recent activity or checkpoint. - Processing statistics and performance (
TotalRecordCount,ProcessedRecordCount,SuccessRecordCount,ErrorRecordCount) – These metrics provide granular insights into the processing efficiency and outcome of the batch job, highlighting data volume, successful processing rates, and error occurrences. - Cost and resource utilization metrics (
InputTokenCount,OutputTokenCount) – Specifically designed for cost analysis, these columns track the consumption of tokens, which is a direct factor in Amazon Bedrock pricing, enabling accurate resource usage assessment. - Data and location management (
InputLocation,OutputLocation) – These columns link the inference job to its source and destination data within Amazon S3, maintaining traceability of the data involved in the batch processing.
View product recommendations
Complete the following steps to open the output file and view the recommendations for each customer generated by the FM:
- On the Amazon Bedrock console, open the completed batch inference job.
- Find the job Amazon Resource Name (ARN) and copy the text after
model-invocation-job/, as illustrated in the following screenshot.
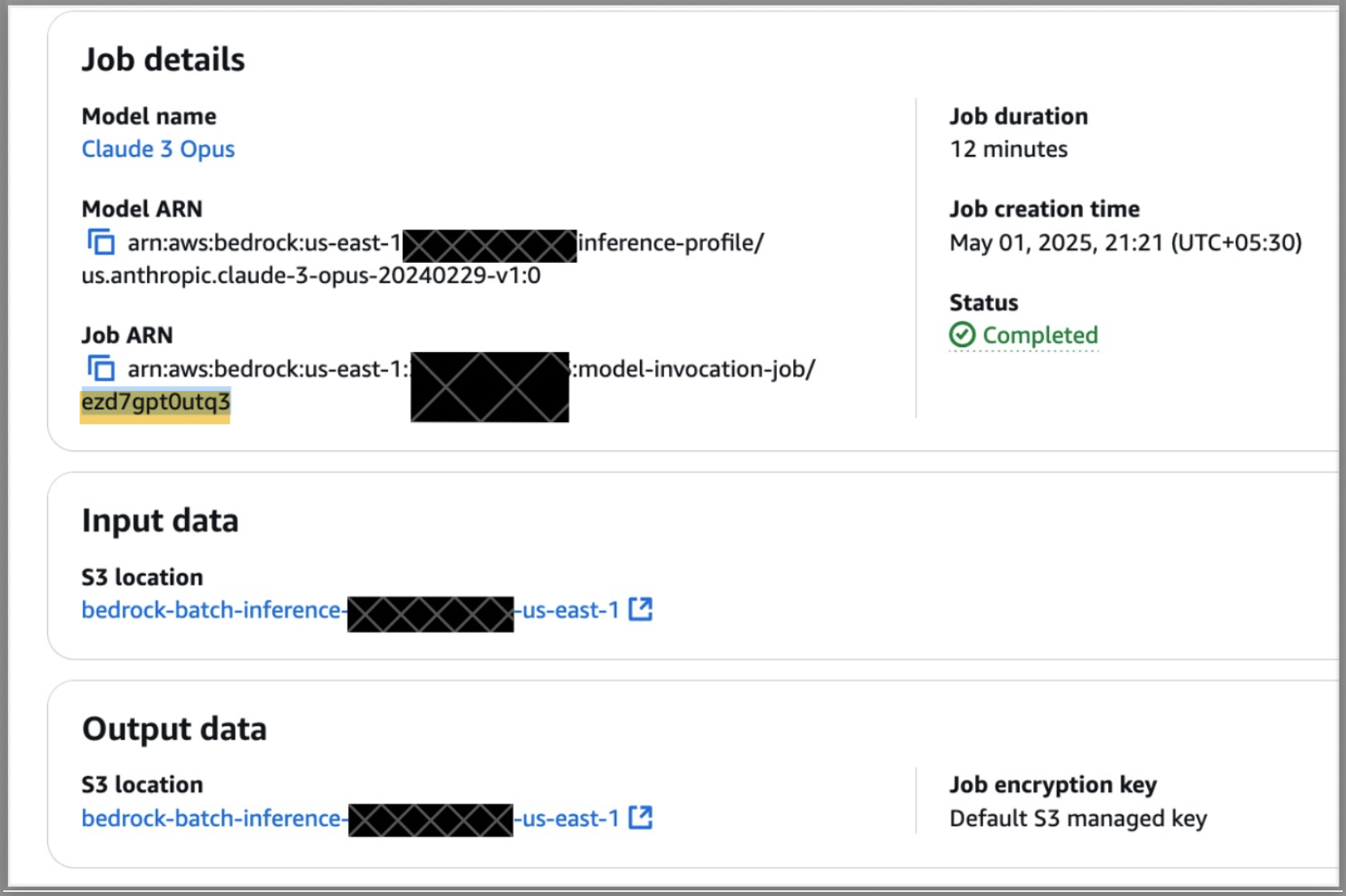
- Choose the link for S3 location under Output data.
A new tab opens with the inference_results folder of the S3 bucket.
- Search for the job results folder using the text copied from the previous step.
- Open the folder to find two output files:
- The file named
manifestcontains information like number of tokens, number of successful records, and number of errors. - The second output file contains the recommendations.
- The file named
- Download the second output file and open it in a text editor like Visual Studio Code to find the recommendations against each customer.
The example in the following screenshot shows several recommended products and why the FM chose this product for the specific customer.

Best practices
To optimize or enhance your monitoring solution, consider the following best practices:
- Set up Amazon CloudWatch alarms for failed jobs to facilitate prompt attention to issues. For more details, see Amazon CloudWatch alarms.
- Use appropriate DynamoDB capacity modes based on your workload patterns.
- Configure relevant metrics and logging of batch job performance for operational visibility. Refer to Publish custom metrics for more details. The following are some useful metrics:
- Average job duration
- Token throughput rate (
inputTokenCount+outputTokenCount) /jobDuration) - Error rates and types
Estimated costs
The cost estimate of running this solution one time is less than $1. The estimate for batch inference jobs considers Anthropic’s Claude 3.5 sonnet V2 model. Refer to Model pricing details for batch job pricing of other models on Amazon Bedrock.
Clean up
If you no longer need this automated monitoring solution, follow these steps to delete the resources it created to avoid additional costs:
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Select the bucket you created and choose Empty to delete its contents.
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Select the created stack and choose Delete.
This automatically deletes the deployed stack and the resources created.
Conclusion
In this post, we demonstrated how a financial services company can use an FM to process large volumes of customer records and get specific data-driven product recommendations. We also showed how to implement an automated monitoring solution for Amazon Bedrock batch inference jobs. By using EventBridge, Lambda, and DynamoDB, you can gain real-time visibility into batch processing operations, so you can efficiently generate personalized product recommendations based on customer credit data. The solution addresses key challenges in managing batch inference operations:
- Alleviates the need for manual status checking or continuous polling
- Provides immediate notifications when jobs complete or fail
- Maintains a centralized record of job statuses
This automated monitoring approach significantly enhances the ability to process large amounts of financial data using batch inference for Amazon Bedrock. This solution offers a scalable, efficient, and cost-effective approach to do batch inference for a variety of use cases, such as generating product recommendations, identifying fraud patterns, or analyzing financial trends in bulk, with the added benefit of real-time operational visibility.
About the authors
 Durga Prasad is a Senior Consultant at AWS, specializing in the Data and AI/ML. He has over 17 years of industry experience and is passionate about helping customers design, prototype, and scale Big Data and Generative AI applications using AWS native and open-source tech stacks.
Durga Prasad is a Senior Consultant at AWS, specializing in the Data and AI/ML. He has over 17 years of industry experience and is passionate about helping customers design, prototype, and scale Big Data and Generative AI applications using AWS native and open-source tech stacks.
 Chanpreet Singh is a Senior Consultant at AWS with 18+ years of industry experience, specializing in Data Analytics and AI/ML solutions. He partners with enterprise customers to architect and implement cutting-edge solutions in Big Data, Machine Learning, and Generative AI using AWS native services, partner solutions and open-source technologies. A passionate technologist and problem solver, he balances his professional life with nature exploration, reading, and quality family time.
Chanpreet Singh is a Senior Consultant at AWS with 18+ years of industry experience, specializing in Data Analytics and AI/ML solutions. He partners with enterprise customers to architect and implement cutting-edge solutions in Big Data, Machine Learning, and Generative AI using AWS native services, partner solutions and open-source technologies. A passionate technologist and problem solver, he balances his professional life with nature exploration, reading, and quality family time.