Picture this: Your team just received 10,000 customer feedback responses. The traditional approach? Weeks of manual analysis. But what if AI could not only analyze this feedback but also validate its own work? Welcome to the world of large language model (LLM) jury systems deployed using Amazon Bedrock.
As more organizations embrace generative AI, particularly LLMs for various applications, a new challenge has emerged: ensuring that the output from these AI models aligns with human perspectives and is accurate and relevant to the business context. Manual analysis of large datasets can be time consuming, resource intensive, and thus impractical. For example, manually reviewing 2,000 comments can take over 80 hours, depending on comment length, complexity, and researcher analyses. LLMs offer a scalable approach to serve as qualitative text annotators, summarizers, and even judges evaluating text outputs from other AI systems.
This prompts the question, “But how can we deploy such LLM-as-a-judge systems effectively and then use other LLMs to evaluate performance?”
In this post, we highlight how you can deploy multiple generative AI models in Amazon Bedrock to instruct an LLM model to create thematic summaries of text responses (such as from open-ended survey questions to your customers) and then use multiple LLM models as a jury to review these LLM generated summaries and assign a rating to judge the content alignment between the summary title and summary description. This setup is often referred to as an LLM jury system. Think of the LLM jury as a panel of AI judges, each bringing their own perspective to evaluate content. Instead of relying on a single model’s potentially biased view, multiple models work together to provide a more balanced assessment.
Problem: Analyzing text feedback
Your organization receives thousands of customer feedback responses. Traditional manual analysis of responses might painstakingly and resource-intensively take days or weeks, depending on the volume of free text comments you receive. Alternative natural language processing techniques, though likely faster, also require extensive data cleanup and coding know-how to analyze the data effectively. Pre-trained LLMs offer a promising, relatively low-code solution for quickly generating thematic summaries from text-based data because these models have been shown to scale data analysis and reduce manual review time. However, when relying on a single pre-trained LLM for both analysis and evaluation, concerns arise regarding biases, such as model hallucinations (that is, producing inaccurate information) or confirmation bias (that is, favoring expected outcomes). Without cross-validation mechanisms, such as comparing outputs from multiple models or benchmarking against human-reviewed data, the risk of unchecked errors increases. Using multiple pre-trained LLMs can address this concern by providing robust and comprehensive analyses, even allowing for enabling human-in-the-loop oversight, and enhancing reliability over a single-model evaluation. The concept of using LLMs as a jury means deploying multiple generative AI models to independently evaluate or validate each other’s outputs.
Solution: Deploy LLM as judges on Amazon Bedrock
You can use Amazon Bedrock to compare the various frontier foundation models (FMs) such as Anthropic’s Claude 3 Sonnet, Amazon Nova Pro, and Meta’s Llama 3. The unified Amazon Web Services (AWS) environment and standardized API calls simplify deploying multiple models for thematic analysis and judging model outputs. Amazon Bedrock also solves for operational needs through a unified security and compliance controlled system and a consistent model deployment environment across all models.
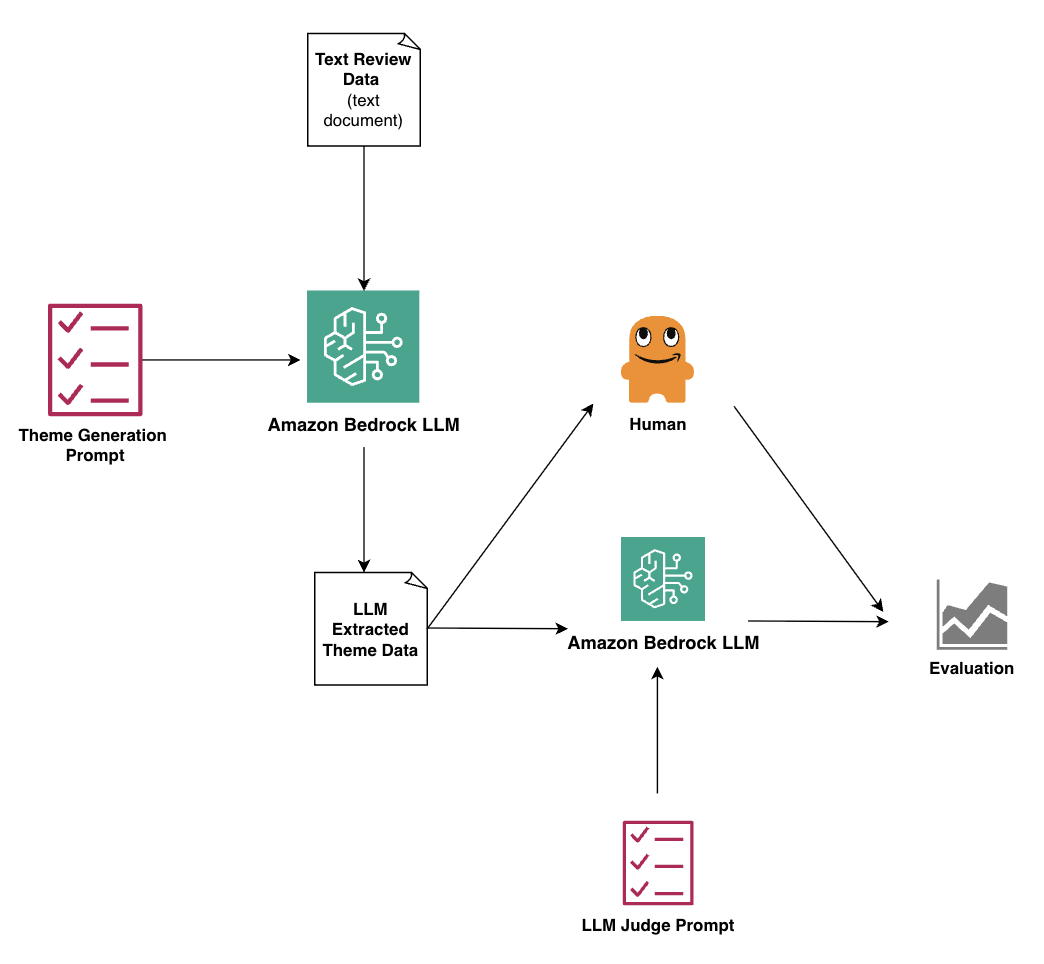
Our proposed workflow, illustrated in the following diagram, includes these steps:
- The preprocessed raw data is prepared in a .txt file and uploaded into Amazon Bedrock. A thematic generation prompt is crafted and tested, then the data and prompt are run in Amazon SageMaker Studio using a pre-trained LLM of choice.
- The LLM-generated summaries are converted into a .txt file, and the summary data is uploaded into SageMaker Studio.
- Next, an LLM-as-a-judge prompt is crafted and tested, and the summary data and prompt are run in SageMaker Studio using different pre-trained LLMs.
- Human-as-judge scores are then statistically compared against the model performance. We use percentage agreement, Cohen’s kappa, Krippendorff’s alpha, and Spearman’s rho.
Prerequisites
To complete the steps, you need to have the following prerequisites:
- An AWS account with access to:
- Amazon Bedrock – Check out Getting Started with Amazon Bedrock.
- Amazon SageMaker AI – Check out Getting Started with Amazon SageMaker AI
- Amazon Simple Storage Service (Amazon S3) – Check out Getting Started with Amazon S3
- Basic understanding of Python and Jupyter notebooks
- Preprocessed text data for analysis
Implementation details
In this section, we walk you through the step-by-step implementation.
Try this out for yourself by downloading the Jupyter notebook from GitHub.
- Create a SageMaker notebook instance to run the analysis, and then initialize Amazon Bedrock and configure the input and output file locations on Amazon S3. Save the text feedback you’d like to analyze as a .txt file in an S3 bucket. Use the following code:
- Use Amazon Nova Pro in Amazon Bedrock to generate LLM-based thematic summaries for the feedback you want to analyze. Depending on your use case, you can use any or multiple models offered by Amazon Bedrock for this step. The prompt provided here is also generic and will need to be tuned for your specific use case to give the LLM model of choice adequate context on your data to enable appropriate thematic categorization:
- You can now use multiple LLMs as jury to evaluate the themes generated by the LLM in the previous step. In our example, we use Amazon Nova Pro and Anthropic’s Claude 3.5 Sonnet models to each analyze the themes per feedback and provide an alignment score. Here, our alignment score is on a scale of 1–3, where 1 indicates poor alignment in which themes don’t capture the main points, 2 indicates partial alignment in which themes capture some but not all key points, and 3 indicates strong alignment in which themes accurately capture the main points:
- When you have the alignment scores from the LLMs, here’s how you can implement the following agreement metrics to compare and contrast the scores. Here, if you have ratings from human judges, you can quickly add those as another set of scores to discover how closely the human ratings (gold standard) aligns with that of the models:
We used the following popular agreement metrics to compare alignment and therefore performance across and among models:
- Percentage agreement – Percentage agreement tells us how many times two raters provide the same rating (for example, 1–5) of the same thing, such as two people providing the same 5-star rating of a movie. The more times they agree, the better. This is expressed as a percentage of the total number of cases rated and calculated by dividing the total agreements by the total number of ratings and multiplying by 100.
- Cohen’s kappa – Cohen’s kappa is essentially a smarter version of percentage agreement. It’s like when two people guess how many of their 5 coworkers will wear blue in the office each day. Sometimes both people guess the same number (for example, 1–5) by chance. Cohen’s kappa considers how well the two people agree, beyond any lucky guesses. The coefficients range from −1 to +1, where 1 represents perfect agreement, 0 represents agreement equivalent to chance, and negative values indicate agreement less than chance.
- Spearman’s rho – Spearman’s rho is like a friendship meter for numbers. It shows how well two sets of numbers “get along” or move together. If one set of numbers goes up and the other set also goes up, they have a positive relationship. If one goes up while the other goes down, they have a negative relationship. Coefficients range from 1 to +1, with values closer to ±1 indicating stronger correlations.
- Krippendorff’s alpha – Krippendorff’s alpha is a test used to determine how much all raters agree on something. Imagine two people taste-testing different foods at a restaurant and rating the foods on a scale of 1–5. Krippendorff’s alpha provides a score to show how much the two people agree on their food ratings, even if they didn’t taste every dish in the restaurant. The alpha coefficient ranges from 0–1, where values closer to 1 indicate higher agreement among raters. Generally, an alpha above 0.80 signifies strong agreement, an alpha between 0.67 and 0.80 indicates acceptable agreement, and an alpha below 0.67 suggests low agreement. If calculated with the rationale that the levels (1, 2, and 3) are ordinal, Krippendorff’s alpha considers not only agreement but also the magnitude of disagreement. It’s less affected by marginal distributions compared to kappa and provides a more nuanced assessment when ratings are ranked (ordinal). That is, although percentage agreement and kappa treat all disagreements equally, alpha recognizes the difference between minor (for example, “1” compared to “2”) and major disagreements (for example, “1” compared to “3”).
Success! If you followed along, you have now successfully deployed multiple LLMs to judge thematic analysis output from an LLM.
Additional considerations
To help manage costs when running this solution, consider the following options:
- Use SageMaker managed Spot Instances
- Implement batch processing for large datasets with Amazon Bedrock batch inference
- Cache intermediate results in Amazon S3
For sensitive data, consider the following options:
- Enable encryption at rest for all S3 buckets
- Use AWS Identity and Access Management (IAM) roles with minimum required permissions
- Implement Amazon Virtual Private Cloud (Amazon VPC) endpoints for enhanced security
Results
In this post, we demonstrated how you can use Amazon Bedrock to seamlessly use multiple LLMs to generate and judge thematic summaries of qualitative data, such as from customer feedback. We also showed how we can compare human evaluator ratings of text-based summaries from survey response data against ratings from multiple LLMs such as Anthropic’s Claude 3 Sonnet, Amazon Nova Pro, and Meta’s Llama 3. In recently published research, Amazon scientists showed LLMs showed inter-model agreement up to 91% compared with human-to-model agreement up to 79%. Our findings suggest that although LLMs can provide reliable thematic evaluations at scale, human oversight continues to remain important for identifying subtle contextual nuances that LLMs might miss.
The best part? Through Amazon Bedrock model hosting, you can compare the various models using the same preprocessed data across all models, so you can choose the one that works best for your context and need.
Conclusion
With organizations turning to generative AI for analyzing unstructured data, this post provides insight into the value of using multiple LLMs to validate LLM-generated analyses. The strong performance of LLM-as-a-judge models opens opportunities to scale text data analyses at scale, and Amazon Bedrock can help organizations interact with and use multiple models to use an LLM-as-a-judge framework.
About the Authors
 Dr. Sreyoshi Bhaduri is a Senior Research Scientist at Amazon. Currently, she spearheads innovative research in applying generative AI at scale to solve complex supply chain logistics and operations challenges. Her expertise spans applied statistics and natural language processing, with a PhD from Virginia Tech and specialized training in responsible AI from MILA. Sreyoshi is committed to demystifying and democratizing generative AI solutions and bridging the gap between theoretical research and practical applications using AWS technologies.
Dr. Sreyoshi Bhaduri is a Senior Research Scientist at Amazon. Currently, she spearheads innovative research in applying generative AI at scale to solve complex supply chain logistics and operations challenges. Her expertise spans applied statistics and natural language processing, with a PhD from Virginia Tech and specialized training in responsible AI from MILA. Sreyoshi is committed to demystifying and democratizing generative AI solutions and bridging the gap between theoretical research and practical applications using AWS technologies.
 Dr. Natalie Perez specializes in transformative approaches to customer insights and innovative solutions using generative AI. Previously at AWS, Natalie pioneered large-scale voice of employee research, driving product and programmatic improvements. Natalie is dedicated to revolutionizing how organizations scale, understand, and act on customer needs through the strategic integration of generative AI and human-in-the-loop strategies, driving innovation that puts customers at the heart of product, program, and service development.
Dr. Natalie Perez specializes in transformative approaches to customer insights and innovative solutions using generative AI. Previously at AWS, Natalie pioneered large-scale voice of employee research, driving product and programmatic improvements. Natalie is dedicated to revolutionizing how organizations scale, understand, and act on customer needs through the strategic integration of generative AI and human-in-the-loop strategies, driving innovation that puts customers at the heart of product, program, and service development.
 John Kitaoka is a Solutions Architect at Amazon Web Services (AWS) and works with government entities, universities, nonprofits, and other public sector organizations to design and scale AI solutions. His work covers a broad range of machine learning (ML) use cases, with a primary interest in inference, responsible AI, and security. In his spare time, he loves woodworking and snowboarding.
John Kitaoka is a Solutions Architect at Amazon Web Services (AWS) and works with government entities, universities, nonprofits, and other public sector organizations to design and scale AI solutions. His work covers a broad range of machine learning (ML) use cases, with a primary interest in inference, responsible AI, and security. In his spare time, he loves woodworking and snowboarding.
 Dr. Elizabeth (Liz) Conjar is a Principal Research Scientist at Amazon, where she pioneers at the intersection of HR research, organizational transformation, and AI/ML. Specializing in people analytics, she helps reimagine employees’ work experiences, drive high-velocity organizational change, and develop the next generation of Amazon leaders. Throughout her career, Elizabeth has established herself as a thought leader in translating complex people analytics into actionable strategies. Her work focuses on optimizing employee experiences and accelerating organizational success through data-driven insights and innovative technological solutions.
Dr. Elizabeth (Liz) Conjar is a Principal Research Scientist at Amazon, where she pioneers at the intersection of HR research, organizational transformation, and AI/ML. Specializing in people analytics, she helps reimagine employees’ work experiences, drive high-velocity organizational change, and develop the next generation of Amazon leaders. Throughout her career, Elizabeth has established herself as a thought leader in translating complex people analytics into actionable strategies. Her work focuses on optimizing employee experiences and accelerating organizational success through data-driven insights and innovative technological solutions.