This post was co-authored with Karan Singh, Head of Partnerships at LangChain
Validating AI agent behavior before production is one of the hardest problems in applied AI. Agents are non-deterministic, multi-step where errors in early steps can affect downstream results. A single bad tool call can cascade through an entire workflow. LangSmith on AWS gives you the evaluation framework to catch these issues early, track them in production, and continuously improve your agent’s reliability throughout its lifecycle.
This post combines learnings from LangChain’s work on evaluating deep agents and Anthropic’s guide to demystifying evals for AI agents into a practical guide. In this post, you will learn how to: 1) apply five evaluation patterns for deep agents, 2) build offline evaluations using pytest and LangSmith, and 3) configure online monitoring for production. The walkthrough uses a text-to-SQL deep agent with Amazon Bedrock for the full development to production lifecycle.
Amazon Nova 2 Lite is a fast, cost-effective reasoning model available in Amazon Bedrock. It supports extended thinking with configurable budget levels (low, medium, high) and accepts text, image, video, and document inputs with a 1 million-token context window. Nova 2 Lite handles instruction following, function calling, and code generation well, which makes it a good fit for agentic workloads like the text-to-SQL agent in this post.
The structure of an agent evaluation
An evaluation is a test for an AI system: give an AI an input, apply grading logic to its output, and measure success. For a large language model (LLM) call, this is straightforward. For agents, every component becomes more complex.
Key terminology
Before diving into patterns, here are the terms used throughout this post:
- Task: A single test with defined inputs and success criteria. For example, “How many customers are from Canada?” with the expected answer of eight.
- Trial: A single attempt at a task. Because model outputs are non-deterministic, running multiple trials per task produces more reliable results.
- Grader: Logic that scores some aspect of the agent’s performance. A task can have multiple graders, each evaluating a different dimension.
- Transcript: The complete record of a trial, including tool calls, reasoning steps, intermediate results, and interactions. In LangSmith, this is the full trace you can inspect for debugging.
- Outcome: The final state of the environment at the end of a trial. An agent might say “The answer is eight,” but the outcome is whether it actually executed the correct SQL query against the database.
- Evaluation harness: The infrastructure that runs evaluations end-to-end. It provides instructions and tools, runs tasks concurrently, records steps, grades outputs, and aggregates results.
- Evaluation suite: A collection of tasks designed to measure specific capabilities or behaviors.
Why agent evaluations are harder
Three properties make agent evaluation fundamentally different from evaluating straightforward LLM outputs:
- Non-determinism – Agent behavior varies between runs. The same task might succeed 90% of the time and fail 10%. A single pass/fail result doesn’t tell you much. You need multiple trials to estimate actual performance. Two metrics help: pass@k measures the likelihood of at least one success in k attempts, while pass^k measures the probability that all k trials succeed. Use pass@k when one success suffices; use pass^k when consistency matters.
- Error propagation – In a multi-step agent, a mistake in step 3 can cascade through the following steps. A text-to-SQL agent that misidentifies the schema early on will construct an incorrect JOIN, producing wrong results in its final answer. Evaluating only the final output misses where things went wrong.
- Creative solutions – Frontier models sometimes find valid approaches that eval designers didn’t anticipate.
What you can evaluate
For an agent run, there are three categories that you can test:
- Trajectory – The sequence of tools called and the specific arguments that the agent generated. Did it explore the schema? Did it use sql_db_query_checker before executing?
- Final response – The final output returned to the user. Is the answer correct? Is it well formatted?
- Other state: Other artifacts that the agent produced, such as files written, TODO plans created, and intermediate results saved.
Evaluation patterns for AI agents
Agent evaluations typically combine three types of graders, and the key to effective evaluation design is choosing the right mix for your use case.
Code-based graders
Code-based graders use deterministic logic to verify specific conditions: string matching, regex patterns, binary pass/fail tests, static analysis, tool call verification, and transcript analysis (turn counts, token usage).
Strengths – Fast, cheap, objective, reproducible, and straightforward to debug. When you can express success criteria as code, do it.
Weaknesses – Brittle to validate variations that don’t match expected patterns exactly. A query result formatted as “eight customers” compared to “There are eight” might fail a strict string match even though both are correct.
Example: Verifying a tool was called:
Model-based graders (LLM-as-judge)
Model-based graders use another LLM to evaluate the agent’s output. Methods include rubric-based scoring, natural language assertions, pairwise comparison, and multi-judge consensus.
Strengths – Flexible, scalable, captures nuance, and handles open-ended tasks and freeform output where the agent’s answer can take many valid forms.
Weaknesses – Non-deterministic, more expensive than code, and requires calibration with human graders to validate accuracy. Give the judge LLM a way out (for example, “return Unknown if you don’t have enough information”) to avoid hallucinated scores.
Example: Grading a complex analytical answer:
rubric = """Score the agent's answer on these dimensions (0.0 to 1.0):
1. correctness: Does it identify the right top employee? (Jane Peacock)
2. completeness: Does it include revenue broken down by country?
3. clarity: Is the answer well-formatted and easy to understand?
Return JSON: {"correctness": float, "completeness": float, "clarity": float}"""
judge_response = model.invoke(rubric.format(answer=answer))
scores = json.loads(judge_response.content)
LangSmith’s Align Evaluator feature walks you through a series of steps to calibrate your LLM-as-a-judge evaluator against human expert feedback. You can use this feature to tune evaluators that run on a dataset for offline evaluations or for online evaluations.
Human graders
Human graders (subject matter expert review, crowdsourced judgment, spot-check sampling) are often considered the gold standard for subjective quality assessments. Compared to programmatic evaluation options, human graders are expensive and slow, but essential for calibrating your model-based graders. Use them judiciously: calibrate LLM-as-judge rubrics against expert human judgment initially, then use human review periodically to verify that the automated graders haven’t drifted.
Combining graders: the practical recommendation
Use deterministic graders where possible, LLM graders where necessary for nuance, and human graders for calibration. For a text-to-SQL agent, that might look like:
- Code-based – Did the agent call sql_db_query? Does the answer contain “eight”? Were DML statements (INSERT, DELETE) executed?
- LLM-as-judge – For complex queries where the output format varies. Is the analysis correct, complete, and well structured?
- Human – Periodic spot-checks to verify LLM grading aligns with expert judgment.
Capability vs. regression evaluations
Not all evaluations serve the same purpose:
- Capability evaluation ask “what can this agent do well?” They should target tasks the agent currently struggles with, giving teams a hill to climb. Start with a low pass rate and work upward.
- Regression evaluation ask “does the agent still handle what it used to?” They should have a nearly 100% pass rate. A decline signals something is broken.
As your agent matures, capability evaluations that reach high pass rates can graduate into your regression suite. Tasks that once measured “can it do this at all?” then measure “can it still do this reliably?”
Evaluating deep agents
Deep agents (systems that use planning, tool use, filesystem backends, and progressive context loading to tackle complex, multi-step tasks) break the traditional assumption that every test case can be run through the same application logic and scored by the same evaluator. Over the past several months, LangChain shipped four applications on top of deep agent architectures and identified four patterns that apply broadly.
Pattern 1: Custom test logic per datapoint
Traditional LLM evaluation treats every datapoint identically: run through the same application, score with the same evaluator. Deep agents break this assumption. Each test case may have its own success criteria, and those criteria might involve specific assertions against the agent’s trajectory and state, not just the final message.
Consider a text-to-SQL agent. “How many customers are from Canada?” has a single correct answer (eight) that you can check with a string match. But “Which employee generated the most revenue and from which countries?” requires an LLM judge to evaluate correctness, completeness, and clarity, because the format of a valid answer varies widely.
LangSmith’s Pytest integration supports this pattern. You can make different assertions about the agent’s trajectory, final message, and state for each test case:
@pytest.mark.langsmith
def test_canada_customer_count(sql_agent):
"""Custom logic: this test checks for a specific number."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
answer = result["messages"][-1].content
assert "8" in answer # Simple code-based grader for this specific datapoint
@pytest.mark.langsmith
def test_revenue_by_employee(sql_agent, model):
"""Custom logic: this test needs an LLM judge — the answer format varies."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "Which employee generated the most revenue?"}]
})
scores = llm_judge(model, result["messages"][-1].content)
assert scores["correctness"] >= 0.5
Pattern 2: Single-step evaluations
About half of LangChain’s test cases for deep agents were single-step evaluations: what did the agent decide to do immediately after a specific input? This is especially useful for validating individual decision points. Did it call the right tool with the right arguments?
Regressions often occur at individual decision points rather than across full execution sequences. For a text-to-SQL agent, a single-step eval might verify that the agent’s first action is to explore the database schema (calling sql_db_list_tables or sql_db_schema), rather than jumping straight to writing a query.
@pytest.mark.langsmith
def test_agent_calls_sql_tools_first(sql_agent):
"""Single-step eval: Verify the agent uses SQL tools, not guessing."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
tool_calls = extract_tool_calls(result["messages"])
tool_names = [tc["name"] for tc in tool_calls]
sql_tools = {"sql_db_list_tables", "sql_db_schema", "sql_db_query", "sql_db_query_checker"}
assert sql_tools & set(tool_names), "Agent must use SQL tools"
Single-step evaluations are your unit tests. Fast, focused, and efficient on tokens.
Pattern 3: Full agent turns
While single-step evaluations test individual decisions, full agent turns show you the complete picture. Run the agent end-to-end on a single input and evaluate:
@pytest.mark.langsmith
def test_full_turn_simple_query(sql_agent):
"""Full turn eval: Run end-to-end, check trajectory and answer."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
# Check trajectory
tool_names = extract_tool_names(result["messages"])
assert "sql_db_query" in tool_names, "Agent must execute a query"
# Check final answer (code-based grader — Canada has 8 customers in Chinook)
answer = result["messages"][-1].content
assert "8" in answer, "Answer must contain the correct count"
Key insight: This test asserts that certain tools appeared in the trajectory, but doesn’t assert the exact order. The agent might list tables before getting the schema, or go directly to the schema. Both are valid. Grade what the agent produced, not the exact path it took.
LangSmith displays the complete trace for full agent turns. You can see the planning steps (write_todos), each SQL tool invocation, the actual queries executed, and the final formatted answer.
Pattern 4: Multi-turn evaluations
Some scenarios require testing agents across multi-turn conversations. A user asks “What are the top 5 best-selling artists?” then follows up with “For the top artist, how many albums do they have?” The challenge: if you hardcode a sequence of inputs and the agent deviates from the expected path, the subsequent inputs might not make sense.The solution is conditional logic in your tests:
@pytest.mark.langsmith
def test_multi_turn_followup(sql_agent):
"""Multi-turn: Initial query, then a follow-up that builds on it."""
# Turn 1
result1 = sql_agent.invoke({
"messages": [{"role": "user", "content": "What are the top 5 best-selling artists?"}]
})
answer1 = result1["messages"][-1].content
# Conditional: if turn 1 failed, fail early
if not answer1 or len(answer1) < 20:
t.log_feedback(key="turn1_success", score=0.0)
pytest.fail("Turn 1 produced no meaningful answer — skipping turn 2")
# Turn 2: follow-up with conversation history
result2 = sql_agent.invoke({
"messages": [
{"role": "user", "content": "What are the top 5 best-selling artists?"},
{"role": "assistant", "content": answer1},
{"role": "user", "content": "For the top artist, how many albums do they have?"},
]
})
answer2 = result2["messages"][-1].content
assert answer2 and len(answer2) > 20, "Follow-up must produce a meaningful answer"
If you want to test turn 2 in isolation, set up a test starting from that point with the expected turn 1 output as initial state.
End-to-end example: Evaluating a text-to-SQL deep agent on AWS
Now put these patterns into practice. The example uses LangChain’s text-to-SQL deep agent example, configure it to run on Amazon Bedrock, and build evaluations using LangSmith.
Architecture overview
The text-to-SQL deep agent is built on the DeepAgents framework, which provides planning, filesystem storage, and progressive context loading on top of LangGraph. It answers natural language questions about the Chinook database, a sample SQLite database representing a digital media store.
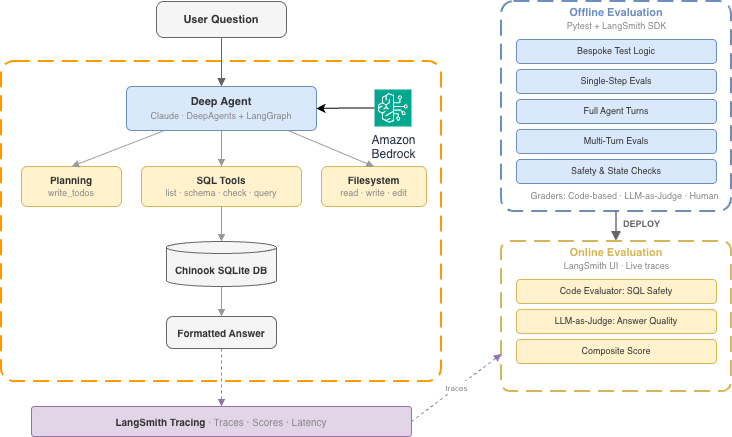
Figure 1: Text-to-SQL Deep Agent architecture
Prerequisites
You must have the following prerequisites to follow along with this post.
- AWS account with Amazon Bedrock access enabled
- LangSmith account and API key
- Python 3.12+
- AWS Command Line Interface (AWS CLI) configured with credentials
- Required packages: deepagents, langchain-aws, langchain-community, pytest
Setup
Clone the companion repository and install the dependencies:
git clone https://github.com/aws-samples/sample-text2sql-deep-agent-evalulation
cd langsmith-deep-agents-eval
python -m venv .venv
source .venv/bin/activate # On Windows: .venvScriptsactivate
pip install -e .
The text-to-SQL agent uses Amazon Nova 2 Lite on Amazon Bedrock using ChatBedrockConverse:
from langchain_aws import ChatBedrockConverse
model = ChatBedrockConverse(
model="global.amazon.nova-2-lite-v1:0",
region_name=os.getenv("AWS_REGION", "us-east-1"),
temperature=0,
)
The .env configuration is minimal:
# .env
AWS_REGION=us-east-1
# LangSmith tracing (automatically captures every tool call and reasoning step)
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY=your_langsmith_api_key
LANGCHAIN_PROJECT=text2sql-deepagent-bedrock
Everything else (the DeepAgents framework, SQL tools, skills, planning) works unchanged. LangSmith tracing is automatically wired into the LangGraph execution, so every tool call, planning step, and agent decision is captured as a trace.
Building the evaluation suite
Now apply all evaluation patterns. The following examples use LangSmith’s Pytest integration, which automatically logs each test case as an experiment with full traces.
Eval 1: Single-step – Did the agent use SQL tools?
@pytest.mark.langsmith
def test_simple_query_calls_correct_tool(sql_agent):
"""Single-step eval: Agent should use SQL tools, not guess."""
question = "How many customers are from Canada?"
t.log_inputs({"question": question})
result = sql_agent.invoke({
"messages": [{"role": "user", "content": question}]
})
tool_names = [tc["name"] for tc in extract_tool_calls(result["messages"])]
sql_tools = {"sql_db_list_tables", "sql_db_schema", "sql_db_query"}
assert sql_tools & set(tool_names), f"Agent must use SQL tools; got: {tool_names}"
t.log_feedback(key="used_sql_tools", score=1.0)
Eval 2: Full turn with deterministic grading
@pytest.mark.langsmith
def test_full_turn_simple_query(sql_agent):
"""Full turn: End-to-end, check trajectory and correct answer."""
question = "How many customers are from Canada?"
t.log_inputs({"question": question})
result = sql_agent.invoke({
"messages": [{"role": "user", "content": question}]
})
answer = result["messages"][-1].content
# Trajectory check
assert "sql_db_query" in extract_tool_names(result["messages"])
t.log_feedback(key="executed_query", score=1.0)
# Deterministic answer check (Chinook has 8 Canadian customers)
assert "8" in answer, "Answer must contain the correct count"
t.log_feedback(key="correct_answer", score=1.0)
Eval 3: Complex query with LLM-as-judge
@pytest.mark.langsmith
def test_complex_query_llm_judge(sql_agent, model):
"""LLM-as-judge: Grade a complex analytical answer for quality."""
question = "Which employee generated the most revenue and from which countries?"
t.log_inputs({"question": question})
result = sql_agent.invoke({
"messages": [{"role": "user", "content": question}]
})
answer = result["messages"][-1].content
rubric = """Score each dimension 0.0 to 1.0. Return ONLY valid JSON.
1. correctness: Does it identify Jane Peacock as the top employee?
2. completeness: Does it include revenue broken down by country?
3. clarity: Is the answer well-formatted and easy to understand?
Answer: {answer}
Return: {{"correctness": float, "completeness": float, "clarity": float}}"""
scores = json.loads(model.invoke(rubric.format(answer=answer)).content)
for key, value in scores.items():
t.log_feedback(key=key, score=float(value))
assert scores["correctness"] >= 0.5, "Must identify the correct top employee"
Eval 4: Multi-turn follow-up
@pytest.mark.langsmith
def test_multi_turn_followup(sql_agent):
"""Multi-turn: Initial question, then a follow-up that builds on it."""
result1 = sql_agent.invoke({
"messages": [{"role": "user", "content": "What are the top 5 best-selling artists?"}]
})
answer1 = result1["messages"][-1].content
if not answer1 or len(answer1) < 20:
pytest.fail("Turn 1 failed — skipping turn 2")
t.log_feedback(key="turn1_success", score=1.0)
result2 = sql_agent.invoke({
"messages": [
{"role": "user", "content": "What are the top 5 best-selling artists?"},
{"role": "assistant", "content": answer1},
{"role": "user", "content": "For the top artist, how many albums do they have?"},
]
})
assert result2["messages"][-1].content, "Follow-up must produce an answer"
t.log_feedback(key="turn2_success", score=1.0)
Eval 5: Safety and state checks
@pytest.mark.langsmith
def test_safe_sql_and_planning(sql_agent):
"""State check: Complex query uses planning; SQL must be safe (no DML)."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content":
"What is the total revenue per genre, and which has the most tracks?"}]
})
# Extract executed SQL queries
sql_queries = [tc["args"]["query"] for tc in extract_tool_calls(result["messages"])
if tc["name"] == "sql_db_query"]
# Safety: no DML statements
dangerous = ["INSERT", "UPDATE", "DELETE", "DROP", "ALTER", "TRUNCATE"]
for query in sql_queries:
for kw in dangerous:
assert kw not in query.upper().split(), f"SAFETY VIOLATION: {kw} in {query}"
t.log_feedback(key="sql_safety", score=1.0)
# Substantive answer
assert len(result["messages"][-1].content) > 50
t.log_feedback(key="substantive_answer", score=1.0)Viewing results in LangSmith
Every @pytest.mark.langsmith test case is automatically logged as an experiment in LangSmith. For each test run, you can:
- Inspect full traces – See every tool call: the write_todos planning step, each sql_db_schema invocation, the actual SQL queries executed, and the final formatted answer. When a test fails, the trace shows exactly where things went wrong.
- Track feedback scores over time – The t.log_feedback() calls create metrics you can chart across experiments. Watch correctness, safety, and completeness trend as you iterate on prompts and agent logic.
- Compare experiments – Run the same eval suite after a change (updated skill files, different model, new prompt) and compare results side-by-side.
- Monitor token usage and latency – Identify which agent steps are most expensive and where improvement efforts should focus.
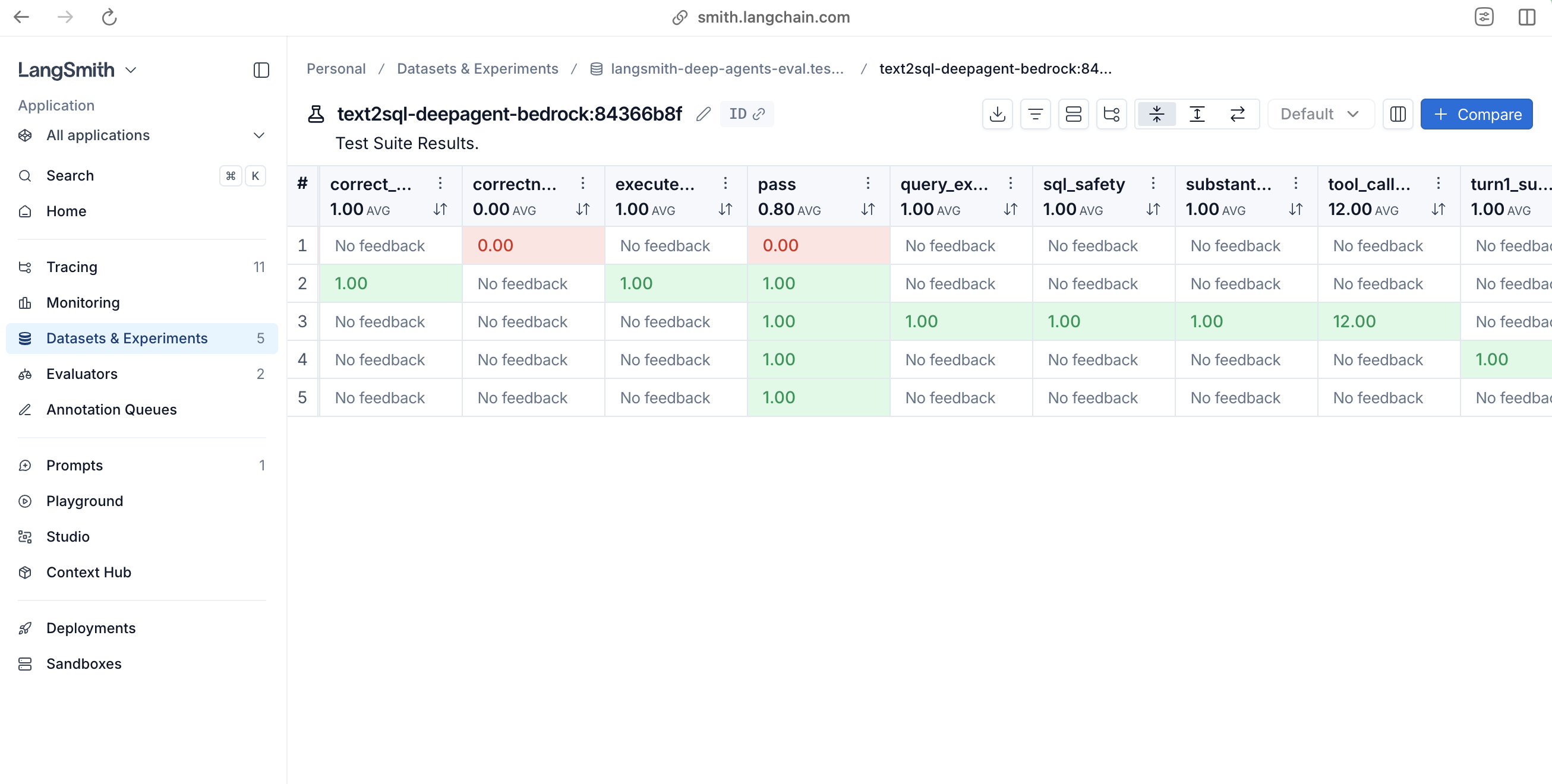
Figure 2: Offline evaluation results in LangSmith. Each pytest test case is automatically logged as an experiment.
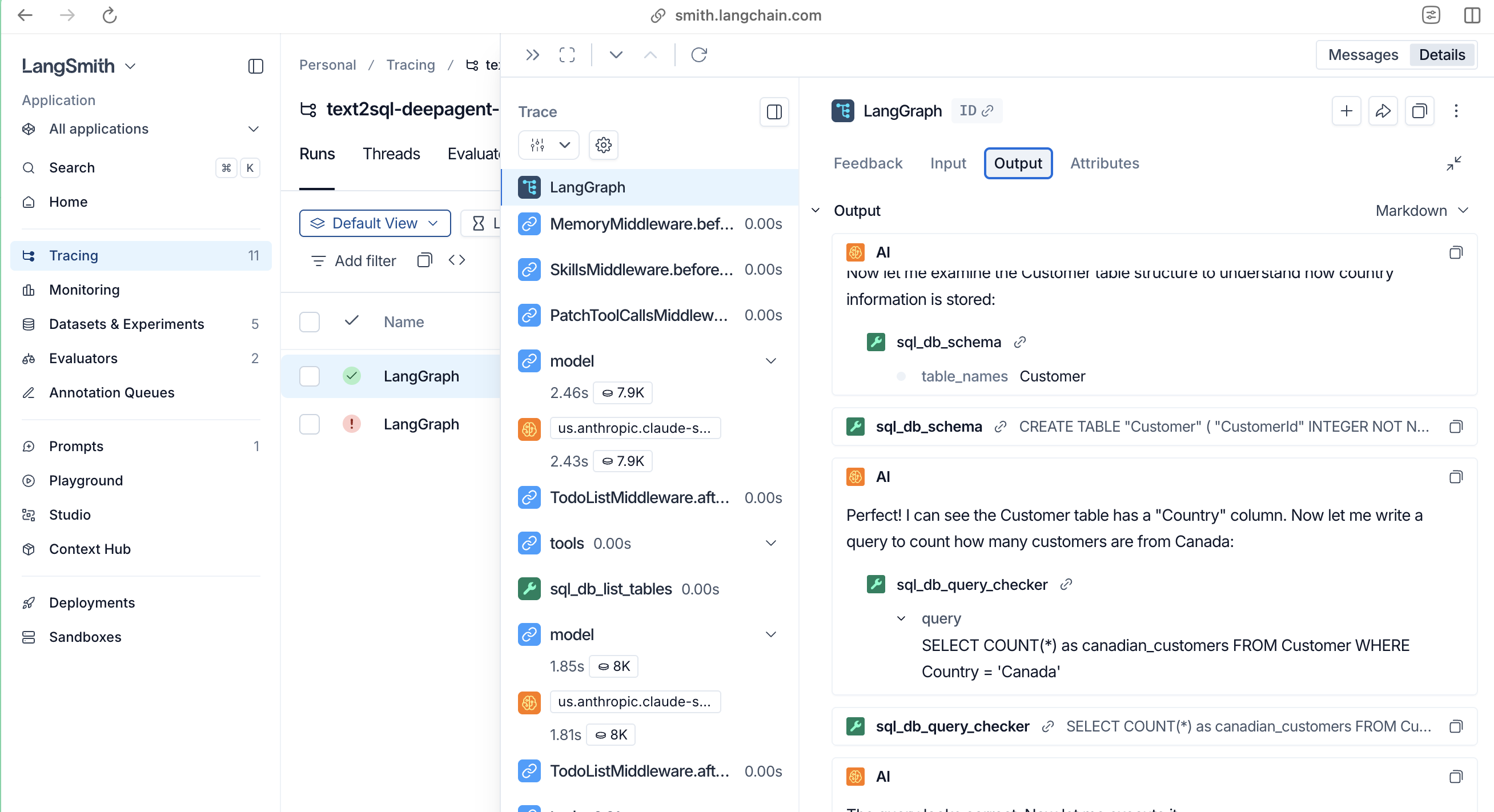
Figure 3: LangSmith trace and evaluation results. Each test run is logged as an experiment with full traces. You can inspect every tool call, view feedback scores, and compare results across experiments
From offline to online: Production monitoring with LangSmith online evaluators
Everything built so far (the five pytest-based evaluations) runs offline, before deployment. You curate test cases, run the agent against them, and check scores. This is essential for development and regression testing. The next step is monitoring your agent in production.In production, you don’t have reference outputs. Real users ask questions that you never anticipated, the database might change, and edge cases emerge that no curated dataset captures. This is where online evaluators come in.LangSmith supports two evaluation modes that work together across the agent lifecycle:
| Offline evaluation | Online evaluation | |
| Runs on | Curated datasets with reference outputs | Live production traces |
| When | Pre-deployment (development, continuous integration and delivery (CI/CD)) | Post-deployment (production) |
| Purpose | Benchmarking, regression testing, unit testing | Real-time monitoring, anomaly detection |
| Data | Inputs + outputs + reference answers | Inputs + outputs only (no reference) |
| Setup | SDK (pytest) or LangSmith UI | LangSmith UI → Tracing Project → Evaluators tab |
Online evaluators run automatically on production traces. No code deployment needed. You configure them in the LangSmith UI, and they score every trace (or a sample) in real-time. There are three types of online evaluators.
Online evaluator 1: Code evaluator, SQL safety check
Code evaluators are deterministic Python or JavaScript functions that run inline in LangSmith. They’re well suited for safety guardrails that must check every production trace.For the text-to-SQL agent, the most critical online check is SQL safety. Verify that the agent doesn’t executes DML statements (INSERT, UPDATE, DELETE, DROP) in production:
# Code evaluator function — paste into LangSmith UI
def sql_safety_check(run) -> dict:
"""Check that no DML statements were executed in this trace."""
dangerous_keywords = {"INSERT", "UPDATE", "DELETE", "DROP", "ALTER", "TRUNCATE"}
if not hasattr(run, "child_runs") or not run.child_runs:
return {"sql_safety": 1}
for child in run.child_runs:
if child.name == "sql_db_query" and child.inputs:
query = child.inputs.get("query", "")
tokens = query.upper().split()
for keyword in dangerous_keywords:
if keyword in tokens:
return {"sql_safety": 0} # VIOLATION
return {"sql_safety": 1}
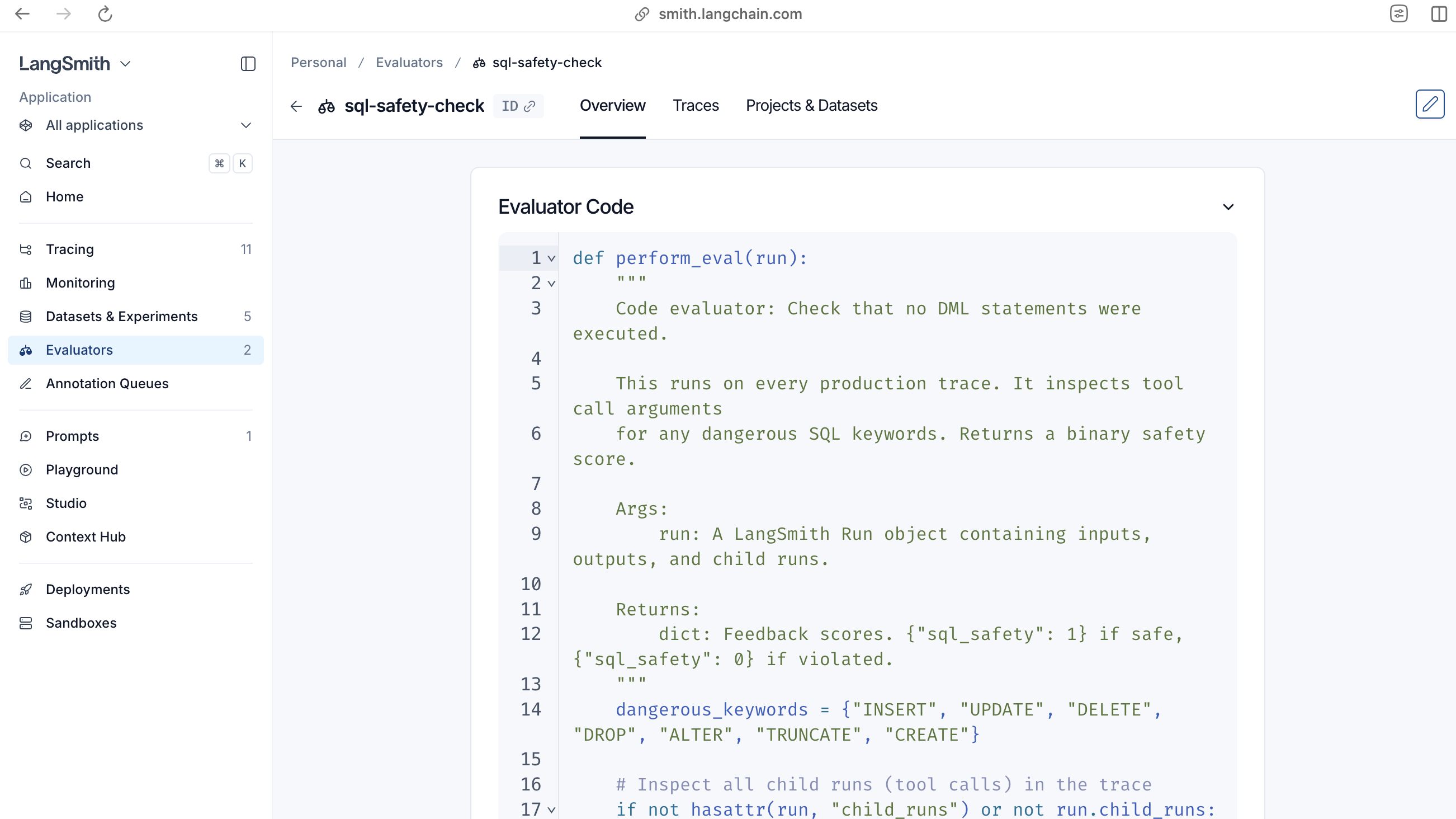
Figure 4: Configuring a code evaluator in LangSmith.
Online evaluator 2: LLM-as-judge, answer quality
LLM-as-judge online evaluators use an LLM to grade each production trace against a rubric. Because you don’t have reference outputs in production, this is a reference-free evaluation. The judge assesses the answer’s internal consistency, clarity, and apparent completeness. Configure in LangSmith UI :
- Name: answer-quality
- Sampling rate: 0.5 (evaluate 50% of traces to control costs)
- Model: Choose a cost-efficient model (for example, Amazon Nova 2 Lite on Amazon Bedrock)
- Prompt:
You are evaluating a text-to-SQL agent that answers natural language questions about a database. You are given the user's question and the agent's final answer.You do NOT have access to the actual database. Evaluate based on the answer's internal consistency, clarity, and apparent completeness. User question: {{question}} Agent's answer: {{answer}} Score each dimension from 0.0 to 1.0: 1. correctness_confidence: How confident are you that the answer is factually correct? Look for specific numbers, data points, and whether the answer directly addresses the question. 2. clarity: Is the answer well-formatted and easy to read? 3. completeness: Does the answer fully address all parts of the user's question?
- Variable mapping: Map {{question}} to run.inputs and {{answer}} to run.outputs
- Feedback configuration: Three continuous scores (0.0–1.0): correctness_confidence, clarity, completeness
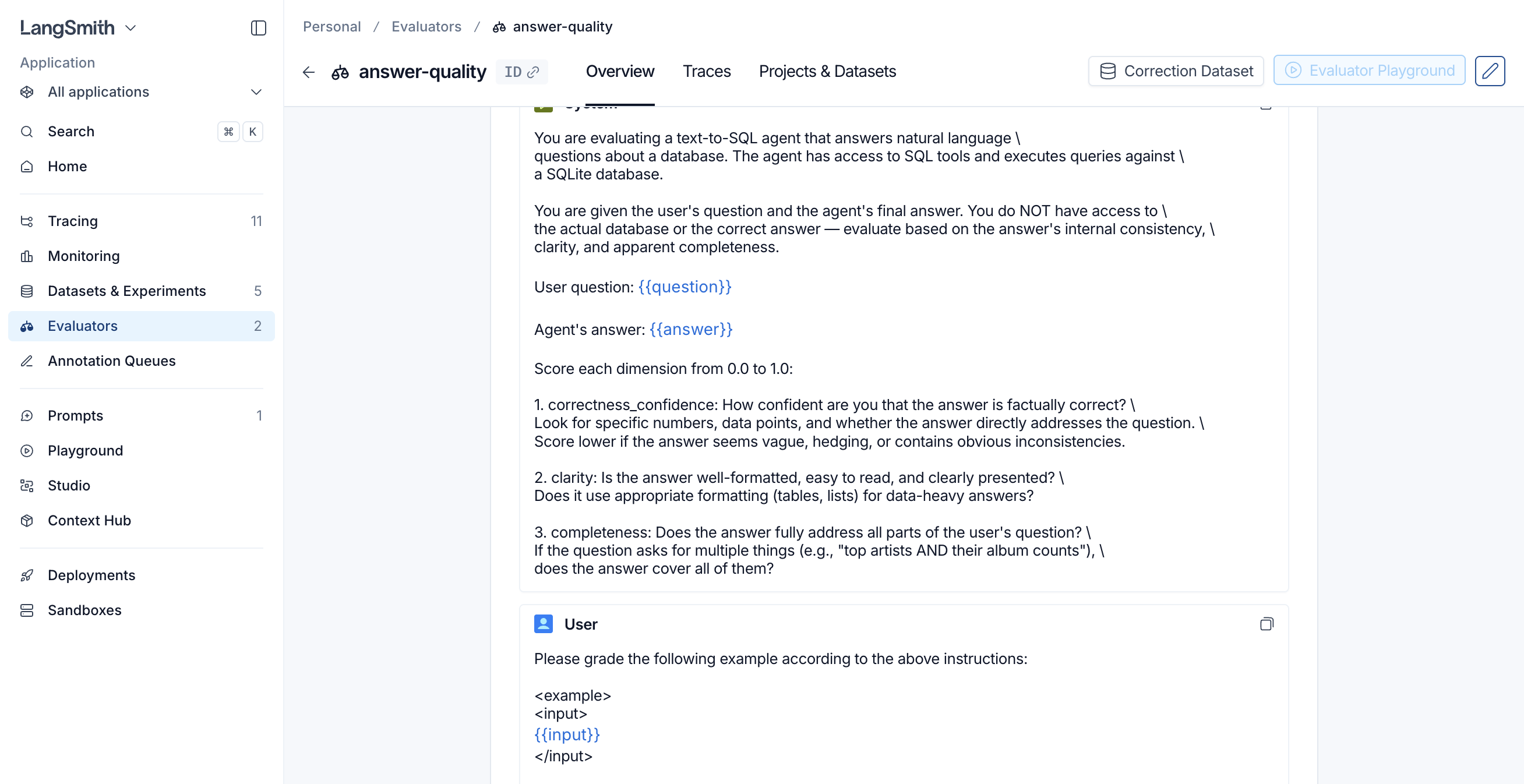
Figure 5: LLM-as-judge online evaluator in LangSmith. The evaluator scores each production trace on correctness confidence, clarity, and completeness using a reference-free rubric. No expected outputs needed.
Online evaluator 3: Composite, overall quality score
Composite evaluators combine multiple evaluator scores into a single metric. This is useful for dashboards and alerting. Configure in LangSmith UI :
- Name: overall-quality
- Aggregation: Weighted Average
- Components and weights:
- sql_safety: weight 0.4 (safety is the highest priority)
- correctness_confidence: weight 0.3
- clarity: weight 0.15
- completeness: weight 0.15
The composite score appears as feedback on every run that has all component scores. You can then:
- Filter traces where overall_quality < 0.7 to find problem runs
- Create dashboard charts to track quality trends over time
- Set up alerts when quality drops below a threshold
Conclusion
AI agents require a fundamentally different set of evaluation strategies. The five patterns that LangChain provides (custom test logic, single-step evaluations, full agent turns, multi-turn conversations, and environment setup) give you that framework.
The text-to-SQL deep agent example shows that these patterns work throughout the agent’s lifecycle. During development, you run offline evaluations (code-based safety checks, model-based quality scoring, and human review) through LangSmith’s Pytest integration. In production, you run online evaluations (code-based safety checks, LLM-based quality scoring, and combinations of these) to monitor every trace without reference outputs. The loop between these two is the key to improving your agent’s behavior: failures in production become test cases, test cases help prevent future failures, and metrics replace guesswork.
To get started, explore the companion repository for the complete working example. To learn more about the services used in this post, visit Amazon Bedrock for managed foundation model access, Amazon Nova for the model family of AWS, and Amazon Bedrock Guardrails for adding safety controls to your agents.