Building AI agents that remember user interactions requires more than just storing raw conversations. While Amazon Bedrock AgentCore short-term memory captures immediate context, the real challenge lies in transforming these interactions into persistent, actionable knowledge that spans across sessions. This is the information that transforms fleeting interactions into meaningful, continuous relationships between users and AI agents. In this post, we’re pulling back the curtain on how the Amazon Bedrock AgentCore Memory long-term memory system works.
If you’re new to AgentCore Memory, we recommend reading our introductory blog post first: Amazon Bedrock AgentCore Memory: Building context-aware agents. In brief, AgentCore Memory is a fully managed service that enables developers to build context-aware AI agents by providing both short-term working memory and long-term intelligent memory capabilities.
The challenge of persistent memory
When humans interact, we don’t just remember exact conversations—we extract meaning, identify patterns, and build understanding over time. Teaching AI agents to respond the same requires solving several complex challenges:
- Agent memory systems must distinguish between meaningful insights and routine chatter, determining which utterances deserve long-term storage versus temporary processing. A user saying “I’m vegetarian” should be remembered, but “hmm, let me think” should not.
- Memory systems need to recognize related information across time and merge it without creating duplicates or contradictions. When a user mentions they’re allergic to shellfish in January and mentions “can’t eat shrimp” in March, these needs to be recognized as related facts and consolidated with existing knowledge without creating duplicates or contradictions.
- Memories must be processed in order of temporal context. Preferences that change over time (for example, the user loved spicy chicken in a restaurant last year, but today, they prefer mild flavors) require careful handling to make sure the most recent preference is respected while maintaining historical context.
- As memory stores grow to contain thousands or millions of records, finding relevant memories quickly becomes a significant challenge. The system must balance comprehensive memory retention with efficient retrieval.
Solving these problems requires sophisticated extraction, consolidation, and retrieval mechanisms that go beyond simple storage. Amazon Bedrock AgentCore Memory tackles these complexities by implementing a research-backed long-term memory pipeline that mirrors human cognitive processes while maintaining the precision and scale required for enterprise applications.
How AgentCore long-term memory works
When the agentic application sends conversational events to AgentCore Memory, it initiates a pipeline to transform raw conversational data into structured, searchable knowledge through a multi-stage process. Let’s explore each component of this system. 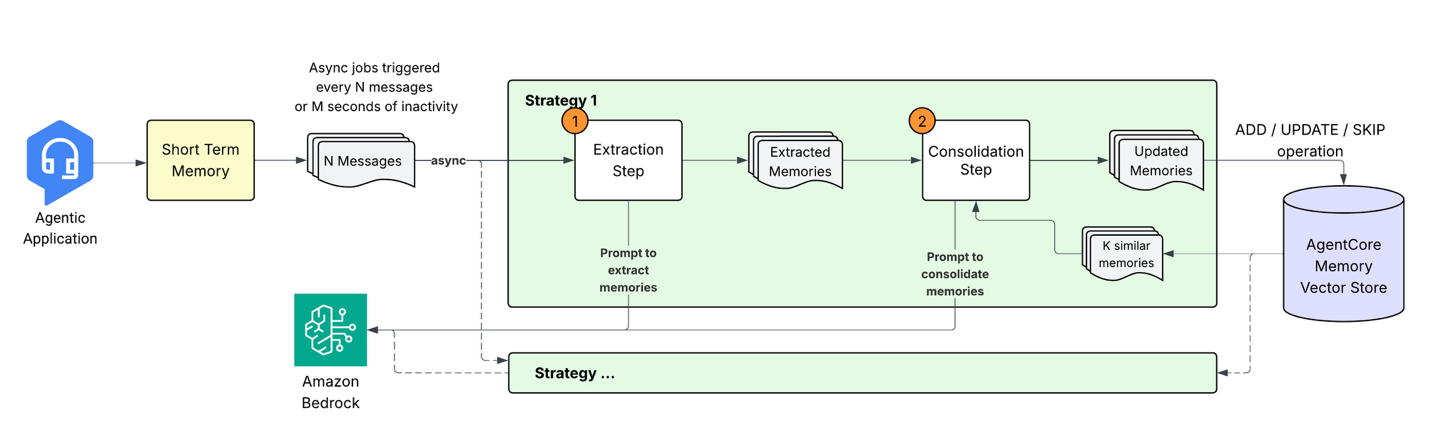
1. Memory extraction: From conversation to insights
When new events are stored in short-term memory, an asynchronous extraction process analyzes the conversational content to identify meaningful information. This process leverages large language models (LLMs) to understand context and extract relevant details that should be preserved in long-term memory. The extraction engine processes incoming messages alongside prior context to generate memory records in a predefined schema. As a developer, you can configure one or more Memory strategies to extract only the information types relevant to your application needs. The extraction process supports three built-in memory strategies:
- Semantic memory: Extracts facts and knowledge. Example:
- User preferences: Captures explicit and implicit preferences given context. Example:
- Summary memory: Creates running narratives of conversations under different topics scoped to sessions and preserves the key information in a structured XML format. Example:
For each strategy, the system processes events with timestamps for maintaining the continuity of context and conflict resolution. Multiple memories can be extracted from a single event, and each memory strategy operates independently, allowing parallel processing.
2. Memory consolidation
Rather than simply adding new memories to existing storage, the system performs intelligent consolidation to merge related information, resolve conflicts, and minimize redundancies. This consolidation makes sure the agent’s memory remains coherent and up to date as new information arrives.
The consolidation process works as follows:
- Retrieval: For each newly extracted memory, the system retrieves the top most semantically similar existing memories from the same namespace and strategy.
- Intelligent processing: The new memory and retrieved memories are sent to the LLM with a consolidation prompt. The prompt preserves the semantic context, thus avoiding unnecessary updates (for example, “loves pizza” and “likes pizza” are considered essentially the same information). Preserving these core principles, the prompt is designed to handle various scenarios:
Based on this prompt, the LLM determines the appropriate action:
- ADD: When the new information is distinct from existing memories
- UPDATE: Enhance existing memories when the new knowledge complements or updates the existing memories
- NO-OP: When the information is redundant
- Vector store updates: The system applies the determined actions, maintaining an immutable audit trail by marking the outdated memories as INVALID instead of instantly deleting them.
This approach makes sure that contradictory information is resolved (prioritizing recent information), duplicates are minimized, and related memories are appropriately merged.
Handling edge cases
The consolidation process gracefully handles several challenging scenarios:
- Out-of-order events: Although the system processes events in temporal order within sessions, it can handle late-arriving events through careful timestamp tracking and consolidation logic.
- Conflicting information: When new information contradicts existing memories, the system prioritizes recency while maintaining a record of previous states:
- Memory failures: If consolidation fails for one memory, it doesn’t impact others. The system uses exponential backoff and retry mechanisms to handle transient failures. If consolidation ultimately fails, the memory is added to the system to help prevent potential loss of information.
Advanced custom memory strategy configurations
While built-in memory strategies cover common use cases, AgentCore Memory recognizes that different domains require tailored approaches for memory extraction and consolidation. The system supports built-in strategies with overrides for custom prompts that extend the built-in extraction and consolidation logic, letting teams adapt memory handling to their specific requirements. To maintain system compatibility and focus on criteria and logic rather than output formats, custom prompts help developers customize what information gets extracted or filtered out, how memories should be consolidated, and how to resolve conflicts between contradictory information.
AgentCore Memory also supports custom model selection for memory extraction and consolidation. This flexibility helps developers balance accuracy and latency based on their specific needs. You can define them via the APIs when you create the memory_resource as a strategy override or via the console (as shown below in the console screenshot).
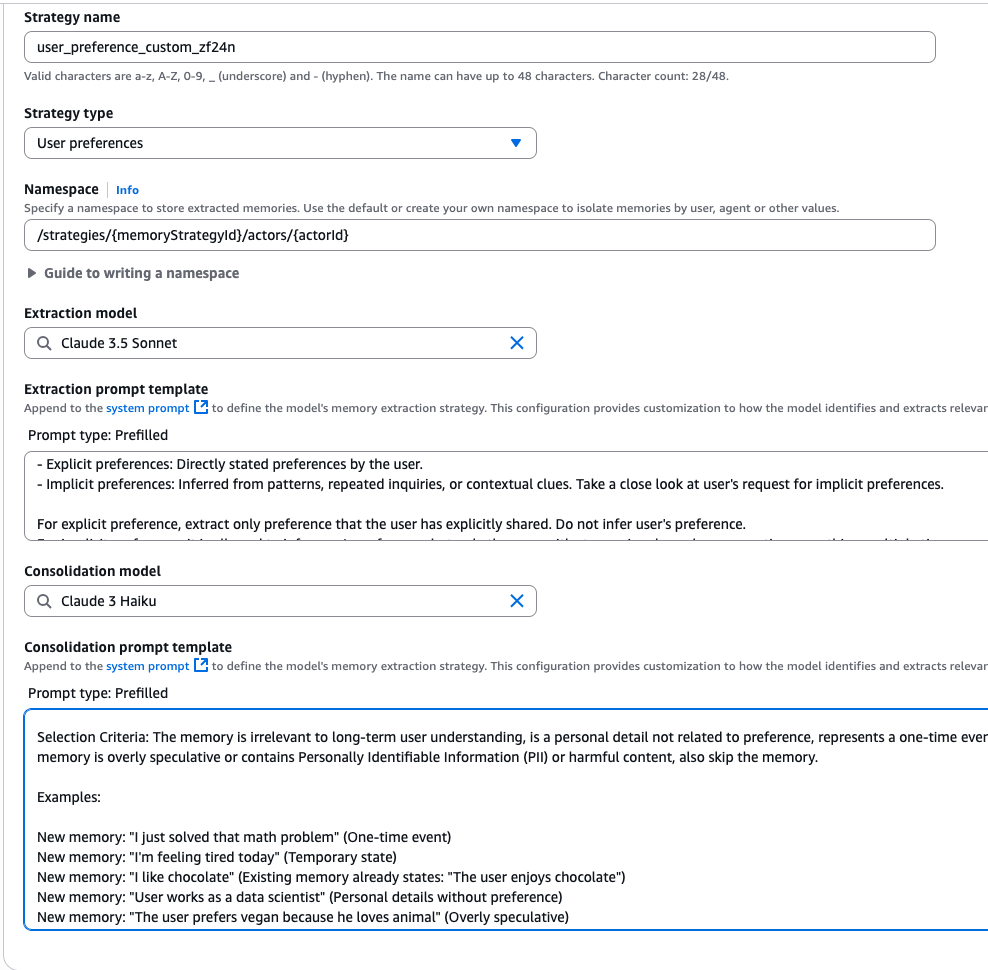
Apart from override functionality, we also offer self-managed strategies that provide complete control over your memory processing pipeline. With self-managed strategies, you can implement custom extraction and consolidation algorithms using any models or prompts while leveraging AgentCore Memory for storage and retrieval. Also, using the Batch APIs, you can directly ingest extracted records into AgentCore Memory while maintaining full ownership of the processing logic.
Performance characteristics
We evaluated our built-in memory strategy across three public benchmarking datasets to assess different aspects of long-term conversational memory:
- LoCoMo: Multi-session conversations generated through a machine-human pipeline with persona-based interactions and temporal event graphs. Tests long-term memory capabilities across realistic conversation patterns.
- LongMemEval: Evaluates memory retention in long conversations across multiple sessions and extended time periods. We randomly sampled 200 QA pairs for evaluation efficiency.
- PrefEval: Tests preference memory across 20 topics using 21-session instances to evaluate the system’s ability to remember and consistently apply user preferences over time.
- PolyBench-QA: A question-answering dataset containing 807 Question Answer (QA) pairs across 80 trajectories, collected from a coding agent solving tasks in PolyBench.
We use two standard metrics: correctness and compression rate. LLM-based correctness evaluates whether the system can correctly recall and use stored information when needed. Compression rate is defined as output memory token count / full context token count, and evaluates how effectively the memory system stores information. Higher compression rates indicate the system maintains essential information while reducing storage overhead. This compression rate directly translates to faster inference speeds and lower token consumption–the most critical consideration for deploying agents at scale because it enables more efficient processing of large conversational histories and reduces operational costs.
| Memory Type | Dataset | Correctness | Compression Rate |
| RAG baseline (full conversation history) |
LoCoMo | 77.73% | 0% |
| LongMemEval-S | 75.2% | 0% | |
| PrefEval | 51% | 0% | |
| Semantic Memory | LoCoMo | 70.58% | 89% |
| LongMemEval-S | 73.60% | 94% | |
| Preference Memory | PrefEval | 79% | 68% |
| Summarization | PolyBench-QA | 83.02% | 95% |
The retrieval-augmented-generation (RAG) baseline performs well on factual QA tasks due to complete conversation history access, but struggles with preference inference. The memory system achieves strong practical trade-offs: though information compression leads to slightly lower correctness on some factual tasks, it provides 89-95% compression rates for scalable deployment, maintaining bounded context sizes, and performs effectively at their specialized use cases.
For more complex tasks requiring inference (understanding user preferences or behavioral patterns), memory demonstrates clear advantages in both performance accuracy and storage efficiency—the extracted insights are more valuable than raw conversational data for these use cases.
Beyond accuracy metrics, AgentCore Memory delivers the performance characteristics necessary for production deployment.
- Extraction and consolidation operations complete within 20-40 seconds for standard conversations after the extraction is triggered.
- Semantic search retrieval (
retrieve_memory_recordsAPI) returns results in approximately 200 milliseconds. - Parallel processing architecture enables multiple memory strategies to process independently; thus, different memory types can be processed simultaneously without blocking each other.
These latency characteristics, combined with the high compression rates, enable the system to maintain responsive user experiences while managing extensive conversational histories efficiently across large-scale deployments.
Best practices for long-term memory
To maximize the effectiveness of long-term memory in your agents:
- Choose the right memory strategies: Select built-in strategies that align with your use case or create custom strategies for domain-specific needs. Semantic memory captures factual knowledge, preference memory tailors towards individual preference, and summarization memory distills complex information for better context management. For example, a customer support agent might use semantic memory to capture customer transaction history and past issues, while summarization memory creates short narratives of current support conversations and troubleshooting workflows across different topics.
- Design meaningful namespaces: Structure your namespaces to reflect your application’s hierarchy. This also enables precise memory isolation and efficient retrieval. For example, use
customer-support/user/john-doefor individual agent memories andcustomer-support/shared/product-knowledgefor team-wide information. - Monitor consolidation patterns: Regularly review what memories are being created (using
list_memoriesorretrieve_memory_recordsAPI), updated, or skipped. This helps refine your extraction strategies and helps the system capture relevant information that’s better fitted to your use case. - Plan for async processing: Remember that long-term memory extraction is asynchronous. Design your application to handle the delay between event ingestion and memory availability. Consider using short-term memory for immediate retrieval needs while long-term memories are being processed and consolidated in the background. You might also want to implement fallback mechanisms or loading states to manage user expectations during processing delays.
Conclusion
The Amazon Bedrock AgentCore Memory long-term memory system represents a significant advancement in building AI agents. By combining sophisticated extraction algorithms, intelligent consolidation processes, and immutable storage designs, it provides a robust foundation for agents that learn, adapt, and improve over time.
The science behind this system, from research-backed prompts to innovative consolidation workflow, makes sure that your agents don’t just remember, but understand. This transforms one-time interactions into continuous learning experiences, creating AI agents that become more helpful and personalized with every conversation.
Resources:
– AgentCore Memory Docs
– AgentCore Memory code samples
– Getting started with AgentCore – Workshop
About the authors
 Akarsha Sehwag is a Generative AI Data Scientist for Amazon Bedrock AgentCore GTM team. With over six years of expertise in AI/ML, she has built production-ready enterprise solutions across diverse customer segments in Generative AI, Deep Learning and Computer Vision domains. Outside of work, she likes to hike, bike or play Badminton.
Akarsha Sehwag is a Generative AI Data Scientist for Amazon Bedrock AgentCore GTM team. With over six years of expertise in AI/ML, she has built production-ready enterprise solutions across diverse customer segments in Generative AI, Deep Learning and Computer Vision domains. Outside of work, she likes to hike, bike or play Badminton.
 Jiarong Jiang is a Principal Applied Scientist at AWS, driving innovations in Retrieval-Augmented Generation (RAG) and agent memory systems to improve the accuracy and intelligence of enterprise AI. She’s passionate about enabling customers to build context-aware, reasoning-driven applications that leverage their own data effectively.
Jiarong Jiang is a Principal Applied Scientist at AWS, driving innovations in Retrieval-Augmented Generation (RAG) and agent memory systems to improve the accuracy and intelligence of enterprise AI. She’s passionate about enabling customers to build context-aware, reasoning-driven applications that leverage their own data effectively.
 Jay Lopez-Braus is a Senior Technical Product Manager at AWS. He has over ten years of product management experience. In his free time, he enjoys all things outdoors.
Jay Lopez-Braus is a Senior Technical Product Manager at AWS. He has over ten years of product management experience. In his free time, he enjoys all things outdoors.
 Dani Mitchell is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS). He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock and Bedrock AgentCore.
Dani Mitchell is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS). He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock and Bedrock AgentCore.
 Peng Shi is a Senior Applied Scientist at AWS, where he leads advancements in agent memory systems to enhance the accuracy, adaptability, and reasoning capabilities of AI. His work focuses on creating more intelligent and context-aware applications that bridge cutting-edge research with real-world impact.
Peng Shi is a Senior Applied Scientist at AWS, where he leads advancements in agent memory systems to enhance the accuracy, adaptability, and reasoning capabilities of AI. His work focuses on creating more intelligent and context-aware applications that bridge cutting-edge research with real-world impact.